Memory Efficiency
In the first section, we discussed the stateful, streaming dataflow model and how to use it to maintain cached state in real time. In this model, both reader and internal nodes of the graph store result sets. Without care, this could lead to an impractical memory footprint.
Readyset solves this problem via partial materialization. You can think of partial materialization as a demand-driven cache filling mechanism that enables Readyset to only store the subset of the overall result set that is useful (i.e., the subset of the results that are commonly read).
What does this look like in practice? Let's come back to the query in the prior section:
SELECT id, author, title, url, vcount
FROM stories
JOIN (SELECT story_id, COUNT(*) AS vcount
FROM votes GROUP BY story_id)
AS VoteCount
ON VoteCount.story_id = stories.id WHERE stories.id = ?;Without partial materialization, Readyset would have to compute the results for this query for every possible input parameter (i.e., for every possible story). This would be pretty unfortunate, because caching the info for every story is not necessary to improve the performance of most applications. In the case of HackerNews, only the first few pages worth of stories are commonly read. Most of the benefit from caching would therefore come from storing this popular content, rather than caching every story ever posted.
With partial materialization, Readyset can compute the query results for specific input parameters when they are requested.
After this initial computation, Readyset will keep those results up-to-date based on writes to the primary database.
For example, after the info for story 42 has been cached, if any users upvote that story, then Readyset will
increment the cached vote count for story 42 by 1 to reflect this data change.
When Readyset is initially deployed, the cache starts off cold and the dataflow graph is entirely empty. During the initial cache warming phase, most queries will be ones that Readyset has never seen before (i.e., cache misses) so Readyset will have to compute their results from scratch.
Readyset computes missing values via upqueries: upon receiving a query for missing state, the reader recursively traverses up the dataflow graph to request its parent nodes for the state required to be able to rederive the missing result set. In the worst case, the upquery has to go all the way up to the base table nodes to retrieve this information. Once it finds the missing state, this state is propagated down the graph.
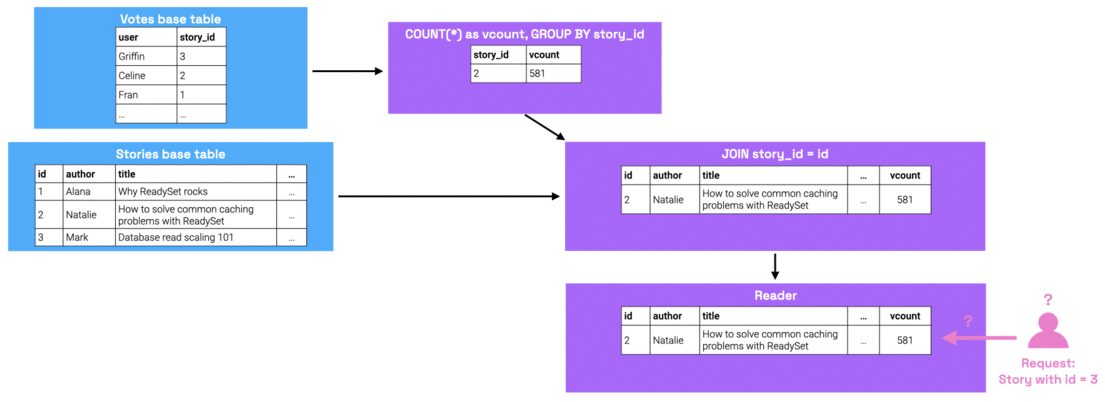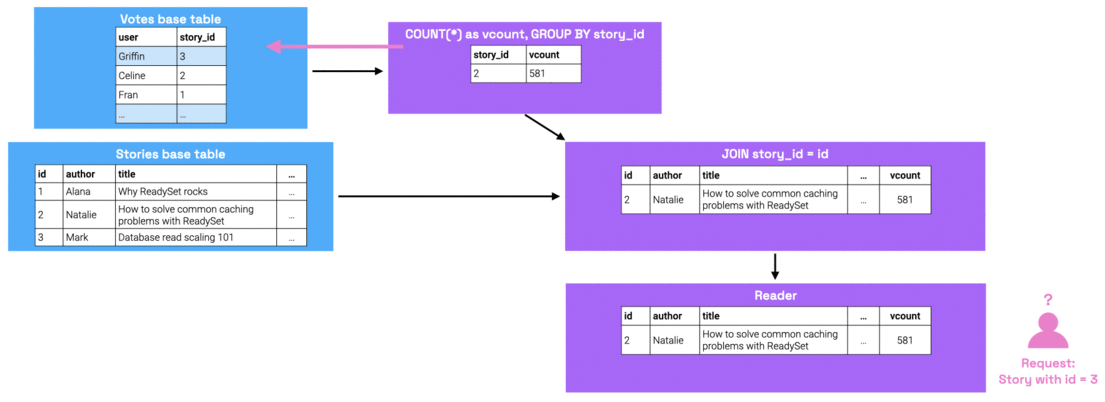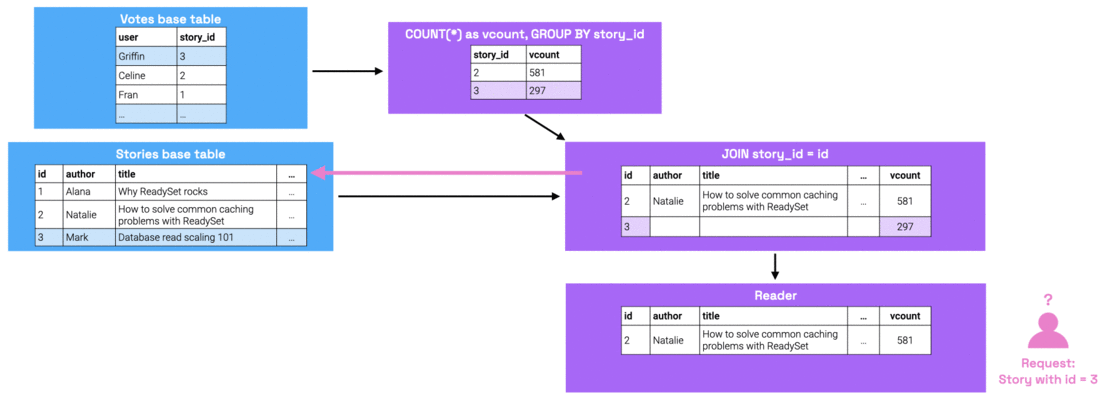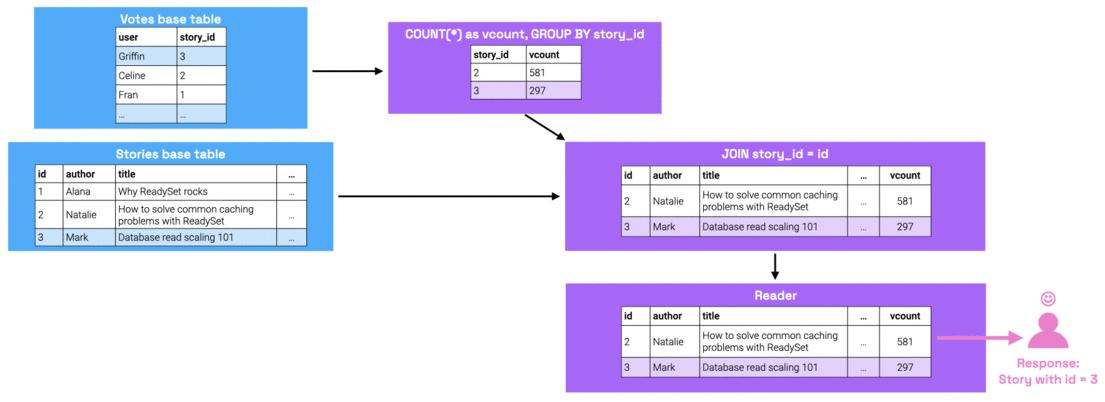
Over time, the frequency with which Readyset sees new input parameters will decrease, given that certain input parameters are much more popular than others. Therefore, the ratio of cache hits vs cache misses will swing in favor of cache hits. Cache hits take less than a millisecond to resolve, so once the cache hit rate is high enough, read performance will dramatically improve.
When you start up Readyset, you give it a memory budget. In most cases, as you continue to use Readyset, the size of the cached state eventually surpasses the budget. From there, Readyset will start to evict cached state. If a query is later run that requests missing results, they are again computed via upquerying.