← Back to blogAI & Databases
Predictions About the Effect of AI on Enterprise Software and Infrastructure
We embarked on an exercise to predict how Enterprise infrastructure (including data infrastructure), will change with AI. Along the way, we made several observations about software and processes in general. I'm noting some of these below. Some of these are fresh takes, and we haven't seen them discussed elsewhere, so we would love to hear different perspectives on them. In this article, we refer to both the use of AI to write software, as well as to execute processes and workflows, i.e. Agents.
Gautam Gopinadhan
2026-01-07 · 5 min read
We embarked on an exercise to predict how Enterprise infrastructure (including data infrastructure), will change with AI. Along the way, we made several observations about software and processes in general. I'm noting some of these below. Some of these are fresh takes, and we haven't seen them discussed elsewhere, so we would love to hear different perspectives on them.
In this article, we refer to both the use of AI to write software, as well as to execute processes and workflows, i.e. Agents.
When referring to Agentic workloads in Enterprise settings, we mean Agents deployed at scale on centralized infrastructure, as a service, rather than as agents running as singletons on individual systems (like coding Agents).
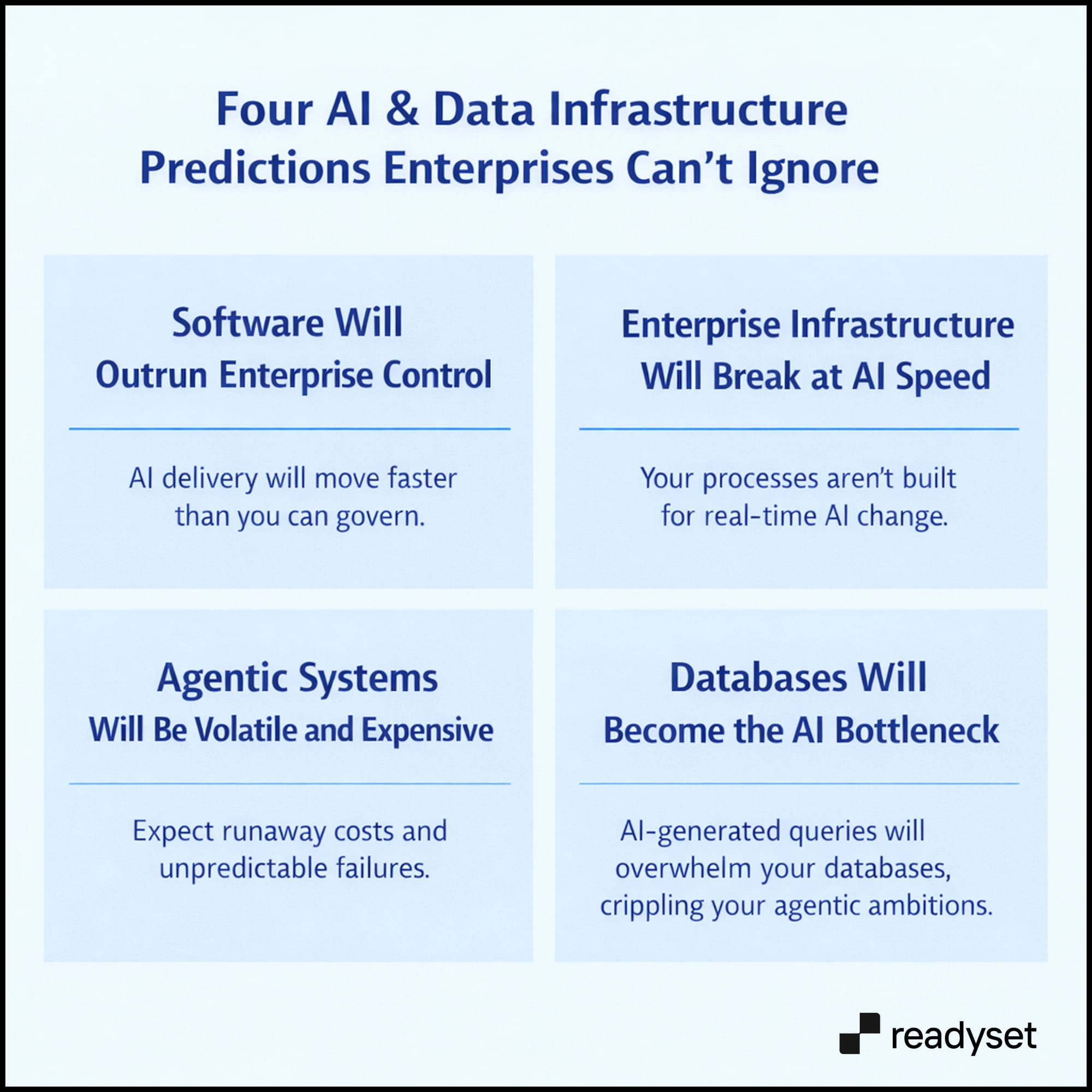
Software Development Will Become Faster — and Harder to Control
AI adoption in enterprises is inevitable
The only real questions are where it lands first and how fast it spreads. The cost benefits and economics, as they stand today, are hard to ignore.
The cost of writing software code is collapsing
With vibe-coding and LLM-assisted development, work that used to take months now takes hours. This is especially true for greenfield projects and domains with well-understood patterns, automation, scripts, tooling, and coordination-heavy systems.
Development velocity is now an even stronger competitive moat
It always mattered, but the gap is widening. If you don’t ship at AI speed, someone else will, and they won’t wait for you to catch up.
Achieving AI speed safely is the real challenge
Most software systems and processes were designed to operate at human speed. Without rethinking review, testing, validation, and deployment, AI-driven velocity simply turns into risk. There’s nothing inherently wrong with AI-generated code but until it undergoes the same scrutiny as human-written code, it quickly becomes AI-slop and a long-term liability.
Feature complexity will increase
Human cognitive limits constrained how complex features and workflows could realistically be. (And this was a good thing!). LLMs can generate code at the speed of thought while retaining large amounts of context, enabling much more complex systems. Over time, some software will only remain serviceable through LLM-assisted development. (We think it makes sense to be cautious when using LLMs to write code in the core systems. Core systems must be easy to reason about, always be dead simple, and ultimately be human-serviceable.)
Feature and tooling abundance will replace scarcity
In application development and tooling, development speedups are already orders of magnitude. As feature costs fall, enterprises will ship far more speculative ideas, knowing that only a small fraction needs to succeed, leading to an abundance of features and tooling.
Enterprise Processes and Infrastructure Will Break Under AI Velocity
AI-generated application code will stress enterprise processes and infrastructure
More shipped features mean more builds, more tests, and more deployments. Expect longer queues in your CI/CD setup. Expect longer code review cycles. Infrastructure, especially databases, will see rapidly changing access patterns than before. Releases will happen more frequently, and each release will unleash fresh data access patterns.
In general, we expect infrastructure costs to spike for Enterprises because of this momentum and complexity.
Guardrails will matter more than raw speed
As delivery accelerates, enterprises need stronger guardrails: more controls, more validation, and more adaptable infrastructure. Brakes and automated verification must exist both at development time and at deployment/runtime.
Auditability moves from “nice-to-have” to “table stakes”
When systems evolve this quickly, you need precise answers to what happened, why it happened, and what changed.
Agentic Systems Will Redefine Scale, Cost, and Volatility
Agents apply AI reasoning to coordination
The same LLM capabilities that generate complex features when embedded in an Agent orchestrate multi-step workflows, interleaving decisions, retries, and exploration.
Agentic systems won’t scale like microservices
Microservices have fixed responsibilities and relatively stable execution paths. Agentic systems are dynamic by nature, varying not just between problems, but between runs of the same problem due to subtle differences in prompts or input data. Scaling solutions for Agentic systems must account for this.
If AI-generated code creates volatility, agents amplify it
Agentic applications will cause even larger swings in access patterns, resource usage, and execution paths. Infrastructure access will be high and rather unpredictable. Databases, in particular, will need to handle large numbers of speculative and potentially expensive queries.
Agentic systems are expensive by default
We suspect that their speculative and exploratory execution models push compute and storage costs far beyond traditional workloads.
Cost-unaware agents will overwhelm infrastructure
Agents that lack awareness of the cost of the operations they trigger can exhaust compute, storage, and database capacity quickly. Agentic systems must be constrained to operate within explicit cost envelopes or, at a minimum, within tightly scoped access boundaries. Simply scaling infrastructure to absorb this behavior, especially when it isn’t cheap, quickly becomes an expensive and unsustainable strategy.
Databases Will Become the Primary Bottleneck for Agentic AI
Caching becomes mandatory, not optional
Context reuse, result sharing, and aggressive memoization across agents are prerequisites for operating agentic systems at scale. Horizontal/vertical scaling approaches are likely not cost-effective in the long term.
Human-built and AI-powered systems will coexist
For a long time, Human-built systems will continue to run because they are easier to reason about. Agentic systems won’t replace deterministic systems, but it may sit on top of them, coordinating more complex workloads by relying on systems that operate on ground truths. Enterprises must assume this.
Data access for agents is fundamentally different
Agents require lower latency, higher fan-out, and far greater adaptability than human-built applications. It might make sense to create sandboxes or data views to regulate what data agents can access.
Giving AI unrestricted write access is dangerous
The risk is obvious, and it’s very real. [Cue: the prescient Sillicon Valley Episode]
Semantic operations are being commoditized
Agents bring built-in reasoning and decision-making capabilities, which naturally expands the use of semantic workloads and operators. Capabilities that once required specialized infrastructure, bespoke pipelines, and significant expertise are now becoming commonplace. This shift is powerful, but it also raises a new challenge. As semantic operations proliferate, there will be increasing pressure to make them dramatically cheaper to execute and operate at scale.
Related articles
Continue reading more about ai & databases.

AI & Databases Readyset Team
Readyset Team
The Real Cost of Read Replicas (and When They Stop Paying Off)
Read replicas are the reflex fix for growing read traffic, but the cost scales linearly with no ceiling. Here's where replicas earn their keep, where they stop paying off, and how SQL-layer caching handles repetitive reads for a fraction of the spend.
Readyset Team2026-07-19·7 min read

AI & Databases Readyset
Readyset
Why LLMs Write Incorrect SQL (and What That Means for Your Database)
Most LLM-generated SQL doesn't fail. It runs and returns results, and that's exactly what makes it dangerous. The errors don't surface until they're already in your data. AI-assisted development has made it easier than ever to generate SQL quickly. The problem is that quick and correct are not the same thing, and with databases, the gap between the two has consequences that compound quietly over time. SQL that runs is not the same as SQL that works. LLMs are good at producing SQL that looks ri
2026-04-23·5 min read

AI & Databases Vinicius Grippa
Vinicius Grippa
Vibe Coding a High-Performance App with Readyset QueryPilot
In this blog post, we are going to use "Vibe Coding" to build an application and explore Readyset QueryPilot, a tool designed to automatically analyze and cache queries in a MySQL workload. The goal is to prove that even for automated queries with no human interaction, QueryPilot can automate query caching and improve performance. QueryPilot automatically identifies which queries should be cached and recommends the appropriate strategy, either deep caching or shallow caching. This automation de
2026-02-24·6 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.