
← Back to blogEngineering
From parser combinators to hand-written TDOP: On adopting sqlparser-rs at Readyset
How Readyset replaced its homegrown SQL parser with sqlparser-rs, improving performance, reducing maintenance overhead, and tackling a years long backlog of parsing edge cases along the way.
Michael Victor Zink
2026-05-21 · 19 min read
Readyset recently shipped an entirely new SQL parsing routine, backed by the excellent sqlparser crate. Dating back to the "thesis days", Readyset/Noria has used its own SQL parser, nom-sql, which takes a parser combinator approach based on the nom crate. This has presented a bit of a maintenance burden, poor performance in the hot path for some workloads, and difficulties in making parsing correct and comprehensive.
This post is a bit of a doozy, but didn't seem worth splitting. We'll cover:
- How parser combinators work by failing
- How a customer's
BETWEENbug report illustrates deeper problems with that approach - How Pratt parsing avoids similar problems entirely (but still isn't perfect for
BETWEEN) - How sqlparser implements Pratt parsing and avoids almost all our nom-sql problems
- A few perf numbers and a really amazing flamegraph
One important disclaimer is that many of the shortcomings of nom-sql we will discuss are not intrinsic to parser combinator libraries or parsers using that approach, and would just need some work to correct (such as error handling, lexing, and memoization). With our existing codebase, the amount and nature of some of that work was not worth it in comparison to switching to a library with amazing community backing, based on fundamental technical choices that seemed to offer better longevity and lower maintenance burden. Plus, it was already faster. Without trying to optimize it, workloads that spend a lot of time on parsing (i.e. no prepared statements, high cache hit rate) showed a 4x increase in overall throughput and 44% reduction in tail latency. Yes, overall throughput and latency, not just in parsing. That's how big of a difference it can make for some workloads.
BETWEEN case study
SQL has a fun operator called BETWEEN. It illustrates many of the problems you face writing a parser, and shows some problems you might run into using parser combinators—so we will use it as a guiding thread. Consider a dashboard query which runs with a few different time ranges, and uses a Postgres :: cast to turn a TIMESTAMP column into a TIME, i.e. extract just the time of day:
mysql=> SELECT kind, count(*)
FROM requests
WHERE requested_at::TIME BETWEEN '16:30' AND '18:29'
GROUP BY kind;
kind | count
------------+-------
automatic | 10
manual | 200
(1 row)
mysql=> SELECT kind, count(*)
FROM requests
WHERE requested_at::TIME BETWEEN '18:30' AND '20:29'
GROUP BY kind;
kind | count
------------+-------
automatic | 400
manual | 50
(1 row)
Well, when a customer tried caching a similar query with Readyset, they saw that it was not supported due to an unfortunate parsing error:
NomSqlError { input: "BETWEEN '18:30' AND '20:29' GROUP BY kind;", offset: 98, line: 3, col: 44, kind: Eof }
You may notice that this doesn't tell us much about why parsing failed; poor error reporting is one of many nom-sql papercuts that factored into our switch. It's also a convenient lens through which to gain some understanding of parser combinators and why this parsing failure represents a deeper problem with the parser.
A comedy of error messages
Let's figure out what this error really means. This is actually a huge spoiler, but I'm going to tell you what the error would look like if sqlparser had an analogous shortcoming in its parsing (it doesn't, but I broke it on purpose for fun):
ParserError("No infix parser for token Word(Word { value: \"BETWEEN\", quote_style: None, keyword: BETWEEN }) at Line: 3, Column: 44")
The difference may be subtle, but it can make a huge difference when debugging your parsing. In nom-sql, we have an Eof error, which basically tells us we were expecting to finish parsing, but there was a remainder. sqlparser at least tells us what we were trying to do when it happened: parse an infix operator.
An even worse example of this kind of problem can be seen when a nested subparser encounters an unexpected token—an even more common occurrence when working on parsers. And keep in mind, some version of these errors is generally surfaced to a user; error messages are part of your UX! Let's try to parse some invalid SQL like SELECT 1 + (bad foobar); and see what happens.
// nom-sql
NomSqlError { input: "+ (bad foobar);", offset: 9, line: 1, col: 10, kind: Eof }
// sqlparser
"Expected: ), found: foobar at Line: 1, Column: 17"
I know which I want to see when a customer says we have a bug in our parser. So why are nom-sql's errors so, uh, bad?
How do you know your parser combinator is broken? It never fails
Parser combinators work by failing. If your parser can allow two different options, you try both parsers and accept the output of the one that doesn't fail. Here's a random example from nom-sql, parsing DROP <table> [ RESTRICT | CASCADE ]:
fn drop_behavior(i: LocatedSpan<&[u8]>) -> NomSqlResult<&[u8], DropBehavior> {
alt((
map(tag_no_case("cascade"), |_| DropBehavior::Cascade),
map(tag_no_case("restrict"), |_| DropBehavior::Restrict),
))(i)
}
alt constructs a parser out of two subparsers. When executed, it first tries the cascade parser. If that fails, it tries the restrict parser. Order matters, and the key thing is: we want to throw away the context of failing subparsers. Since the drop behavior option is optional (wrapped in opt), even if the drop_behavior parser produced a nice error message, the caller would just discard it. The end result, as we've seen, is often poor error messages—errors lose meaningful context as they propagate up the stack.
Here's where it really bites us. This is nom-sql's between parser:
fn between_expr(dialect: Dialect) -> impl Fn(LocatedSpan<&[u8]>) -> NomSqlResult<&[u8], Expr> {
move |i| {
let (i, operand) = map(between_operand(dialect), Box::new)(i)?;
let (i, _) = whitespace1(i)?;
let (i, not) = opt(terminated(tag_no_case("not"), whitespace1))(i)?;
let (i, _) = tag_no_case("between")(i)?;
let (i, _) = whitespace1(i)?;
let (i, min) = map(simple_expr(dialect), Box::new)(i)?;
let (i, _) = whitespace1(i)?;
let (i, _) = tag_no_case("and")(i)?;
let (i, _) = whitespace1(i)?;
let (i, max) = map(between_max(dialect), Box::new)(i)?;
Ok((i, Expr::Between { operand, min, max, negated: not.is_some() }))
}
}
🌌 Quick aside: one reason nom-sql is slow is there's no lexing/tokenization pass. In addition to performance, another consequence of this is that we have to manually handle whitespace every step of the way. When I checked a few months ago, we had 993 whitespace handling calls like whitespace1/whitespace0 above, accounting for almost 5% of the total parser code. And this function is 40% whitespace handling! And yes, using whitespace1 when you should have used whitespace0 and other whitespace handling subtleties have caused several bugs over the years.
The shape is <between_operand> [NOT] BETWEEN <simple_expr> AND <between_max>, with three distinct subparsers for three subexpressions, even though all 3 positions should be able to parse any arbitrary expressions. And between_operand is quite limited:
fn between_operand(dialect: Dialect) -> impl Fn(LocatedSpan<&[u8]>) -> NomSqlResult<&[u8], Expr> {
move |i| {
alt((
parenthesized_expr(dialect),
map(function_expr(dialect), Expr::Call),
map(literal(dialect), Expr::Literal),
case_when_expr(dialect),
map(column_identifier_no_alias(dialect), Expr::Column),
))(i)
}
}
Now it's obvious why the original dashboard query didn't work: no Postgres-style :: cast expressions, so requested_at::TIME BETWEEN ... isn't recognized by any of these alt branches. But you might wonder: why does the error message point at BETWEEN and not at ::TIME? The answer is in how between_expr is invoked:
pub(crate) fn expression(dialect: Dialect)
-> impl Fn(LocatedSpan<&[u8]>) -> NomSqlResult<&[u8], Expr>
{
move |i| {
alt((
map(token_tree(dialect), |tt| {
ExprParser.parse(&mut tt.into_iter()).unwrap()
}),
simple_expr(dialect), // between_expr lives in here
))(i)
}
}
Yikes. We actually have two competing expression parsers: token_tree (which handles binary/unary operators and does recognize :: casts) and simple_expr (which contains between_expr and others). When we try to parse requested_at::TIME BETWEEN '16:30' AND '18:29', the token_tree parser goes first, successfully parses requested_at::TIME as a cast expression, and returns it—without ever seeing BETWEEN; and we never even attempt between_expr.
The selection parser we are inside of at this point is satisfied that it's gotten a complete WHERE clause (any expression will do), then continues with BETWEEN '18:30' AND '20:29' GROUP BY kind; as its remaining input. Everything after the WHERE clause is optional (GROUP BY, HAVING, etc.), so those parsers all gracefully fail, and we end up trying to match eof against a non-empty remainder. Hence, in the original error: kind: Eof.
The key problem is this split between token_tree and simple_expr. There are expressions parseable only as a token_tree (like :: casts), and expressions parseable only as a simple_expr (like BETWEEN). A simple expression starting with a tree expression causes token_tree to claim it, and between_expr never gets a chance.
However, this split is also the only way that we are able to support between expressions at all. Again, the way that we parse BETWEEN expressions is with three distinct sub-parsers for different classes of expressions:
between_operand: have to make sure not to parse theBETWEEN, so we are extremely conservative and basically just parse parens, functions, literals, and identifiers. Oof.[NOT] BETWEEN simple_expr: have to make sure not to parse theAND, so we don't attempt to parse anything with binary operators. Honestly, I'm amazed no customers ran into this limitation before.AND between_max: in order to respect the binding strength of between'sAND, we literally call another varianttoken_tree_no_and_or, just slightly more general thansimple_expr. Hey, at least you can do math here!
We could just chalk this up to somebody forgetting to add :: cast expressions into between_operand, but this should make it clear that we are incorrectly rejecting wide swaths of valid SQL syntax just because we are handling BETWEEN in this weird way. (It's not the only weird case, either; we have a lot of special handling for CASE ... WHEN to paper over similar problems, for example.)
So let's look at what sqlparser does differently.
One loop to rule them all, and in the precedence bind them
So the core problem: nom-sql has numerous separate expression parsers (most importantly token_tree, simple_expr, but also between_operand etc.) that recognize different subsets of SQL expressions, and BETWEEN causes incomplete parses when its left operand happens to be one that only token_tree knows about. The fix isn't to keep adding expression types to between_operand. What we need to do is find a more principled way to respect our precedence rules.
sqlparser achieves this with a technique called Pratt parsing (or Top-Down Operator Precedence, TDOP). The idea, from Vaughan Pratt's 1973 paper, is that instead of encoding operator precedence implicitly through the nesting structure of your grammar (which is what parser combinators naturally do), you make it explicit. Every operator gets a numeric binding power (precedence), and a single recursive function handles all expressions by deciding, at each step, whether the next operator binds tightly enough to claim the current operand.
🤔 token_tree actually implements Pratt parsing itself! However, it has some other uninteresting limitations that would make it difficult to parse some things, which is why it's not used everywhere and we have simple_expr too. We could fix it, but that work just gets tossed atop the growing pile of uninteresting nom-sql problems that sqlparser doesn't have to solve. (The issue here is that BETWEEN is a ternary operator, and the existing API in token_tree doesn't have a way to encode that, such that it would basically be a rewrite.)
So, uh, yeah, you just write down the precedence for all your infix operators, then Pratt parsing looks roughly like this:
parse_expr(min_precedence):
left = parse_prefix() // a number, identifier, unary op, etc.
while next_op has precedence >= min_precedence:
op = consume next_op
right = parse_expr(op.precedence + 1)
left = make_node(left, op, right)
return left
That's it. The parse_prefix call (Pratt called this nud, for "null denotation", aka "I have nothing to my left") handles anything that starts an expression: a literal, an identifier, a unary operator, a parenthesized subexpression, etc.. The loop handles infix operators (led, for "left denotation", aka "I have something to my left") by checking whether the next operator's precedence is high enough to "steal" the current left-hand side.
🔍 We're just looking at simplistic SQL here and assuming everything is left associative; a more general Pratt parser would do something fancier than op.precedence + 1. Check Wikipedia for more detailed pseudocode of the general algorithm.
A concrete walkthrough tree climbthrough: 1 - 2 * 3 + 4
Example time! We call parse_expr(0) and the token stream is 1 - 2 * 3 + 4. In the diagrams that follow, operators are color-coded by precedence: + and - are precedence 1 (yellow), * and / are precedence 2 (red), and number literals are leaves (blue). I always get confused by up, down, left, right, plus, minus, etc. so let's be clear about the visual metaphor here: "lower binding power" means "lower numerical precedence", but corresponds to "higher in the AST" or "closer to the root". So as we go through the loop, precedence starts at 0, goes up to 1; but the mapping to the AST means we start down at the leaves then go up to the lower precedence. Confused? Great, let's dive in.
🤖 Disclaimer: Although this post was lovingly hand-em-dashed by yours truly, I really didn't want to draw any diagrams (too much pointing and clicking which I'm bad at), so I asked Claude to spit out some SVGs for me based on the example.

Step 1: We start with an empty AST. parse_prefix() consumes 1, producing a leaf node. Then we enter the while loop and look at the next token: -.

Step 2: - has precedence 1, which is ≥ 0 (our min_precedence), so we consume it and recurse: parse_expr(2). Importantly, we recurse with a higher min_precedence, meaning only operators that bind tighter than - can claim whatever we parse next.
Inside the recursive call, parse_prefix() consumes 2. Now we look at *.

Step 3: * has precedence 2, which is ≥ 2 (our current min_precedence), so it can steal 2 from -. We consume * and recurse again: parse_expr(3). Inside that call, parse_prefix() consumes 3. The next token is +, with precedence 1—which is less than 3. So the inner loop stops. We return 2 * 3 as a completed subtree back to the call that was building the right side of -.

Step 4: Now we're back in the call handling -. Its right-hand side is 2 * 3. The next token is still +, with precedence 1, which is less than 2 (the min_precedence for -'s right side). So - completes too, and we return 1 - (2 * 3) back to the outermost call.
At the outermost level (min_precedence 0), + has precedence 1, which is ≥ 0, so it claims 1 - (2 * 3) as its left operand. We recurse for its right side.

Step 5: parse_prefix() consumes 4. No more tokens, so that becomes the right subtree of +, and the loop exits. The final AST is (1 - (2 * 3)) + 4.
Notice that + and - share the same precedence, yet the result left-associates: (1 - (2 * 3)) + 4, not 1 - ((2 * 3) + 4). This falls out of the + 1 in the recursive call—by requiring strictly higher precedence, same-precedence operators can't steal from each other, so the outer loop claims them instead, building the tree leftward. Or as Pratt put it: "always associate to the left unless it doesn't make sense." Here, the difference is (1 - 6) + 4 = -1 vs 1 - (6 + 4) = -9.
How sqlparser actually does it
In sqlparser, this looks like:
/// Parse tokens until the precedence changes.
pub fn parse_subexpr(&mut self, precedence: u8) -> Result<Expr, ParserError> {
let mut expr = self.parse_prefix()?;
loop {
let next_precedence = self.get_next_precedence()?;
if precedence >= next_precedence {
break;
}
expr = self.parse_infix(expr, next_precedence)?;
}
Ok(expr)
}
(parse_expr() just calls parse_subexpr(0); and this is only very slightly simplified, just deleted a few uninteresting lines. Makes me wonder why I even bothered with pseudocode above...)
parse_prefix handles literals, identifiers, unary operators, subqueries, and all the other things that can start an expression. parse_infix handles binary operators, IS NULL, IN, LIKE... so what about BETWEEN?
Well, BETWEEN is just another infix operator:
/// Parses `BETWEEN <low> AND <high>`, assuming the `BETWEEN` keyword was already consumed.
pub fn parse_between(&mut self, expr: Expr, negated: bool) -> Result<Expr, ParserError> {
// Stop parsing subexpressions for <low> and <high> on tokens with
// precedence lower than that of `BETWEEN`, such as `AND`, `IS`, etc.
let low = self.parse_subexpr(self.dialect.prec_value(Precedence::Between))?;
self.expect_keyword_is(Keyword::AND)?;
let high = self.parse_subexpr(self.dialect.prec_value(Precedence::Between))?;
Ok(Expr::Between {
expr: Box::new(expr),
negated,
low: Box::new(low),
high: Box::new(high),
})
}
Really, the only quirk is that it recurses twice, since it's ternary, for left and right of the AND. But because BETWEEN has a precedence level, we can just hand that to parse_subexpr.
The expr parameter is the left operand that was already parsed by the time we see BETWEEN. It doesn't matter whether it's a column reference, a function call, a Postgres-style :: cast, or anything else. The single parse_expr loop already handled all of that before recognizing BETWEEN as the infix operator. There is no between_operand parser; all 3 expression positions are maximally general while obeying the precedence rules.
😱 Well, almost maximally general. Although the Pratt approach is an improvement over nom-sql's proliferation of subparsers, it's not quite right either. PostgreSQL's own grammar doesn't actually use a single precedence threshold for BETWEEN's bounds—its yacc grammar uses a restricted nonterminal called b_expr for the low bound:
a_expr BETWEEN opt_asymmetric b_expr AND a_expr %prec BETWEEN
b_expr is a curated subset of expressions that includes arithmetic and comparison operators (<, >, =, etc.) but excludes LIKE, IS NULL, NOT, AND, and OR. This isn't defined by a precedence cutoff; it's an entirely separate grammar production. In PostgreSQL's precedence hierarchy, LIKE has higher precedence than comparison operators, so there's no single numeric threshold that admits = while rejecting LIKE. Using only precedence numbers in a pure Pratt parser, parse_subexpr(precedence) can only express "everything above this number" but not "these specific operators but not those." That may work for most of the SQL dialects sqlparser supports, but not PostgreSQL. Unfortunately, sometimes you have no choice but to step outside the simpler Pratt framework to match what databases actually accept. But as with everything else in our decision to switch, sqlparser is starting from a better place already, and fixing that gap is much easier than in nom-sql. If you're interested in contributing, this could be a nice issue to fix in sqlparser (if we don't get to it first)!
This is why when I deliberately broke sqlparser to not recognize BETWEEN in parse_infix, the error message said "No infix parser for token BETWEEN"—it had already successfully parsed requested_at::TIME as the left-hand side, and was looking for an infix operator to continue the expression. It found BETWEEN and didn't know what to do with it. That's a much more useful place to be stuck than nom-sql's situation, where we never even got close to parsing BETWEEN because a completely different parser ate the left operand, and it was basically a coincidence that BETWEEN was even in the error message.
Results and performance
So sqlparser gives (usually) better error messages, a single expression parser that doesn't have these weird coverage gap warts, and in my opinion a cleaner architecture overall. Furthermore, its design is fundamentally more performance friendly.
The first benchmark we ran of an "ad-hoc simple select" workload—i.e. high cache hit rates and no prepared statements, the worst case scenario for parsing overhead—showed a 3x increase in overall throughput and 44% reduction in tail latency after the switch. A sysbench point select test showed a 4x increase in throughput. These are end-to-end numbers, not microbenchmarks of parsing alone. Readyset caches query results and serves them directly from memory, so for cached queries, parsing is one of the few things that actually happens on each request. When your parser gets orders of magnitude faster, you tend to notice.

Part of this comes from the Pratt approach itself—one forward pass through a token stream, no backtracking, no trying five different subparsers until one succeeds. Part of it comes from sqlparser having a lexer, so the parser works with tokens rather than doing repeated case-insensitive byte matching against raw input.
To illustrate just how big this performance gap is, and why this is tied to the "work by failing" approach of parser combinators, consider this flamegraph. This is from a microbenchmark parsing SELECT * FROM t WHERE id = ?;, about as simple as you can get.
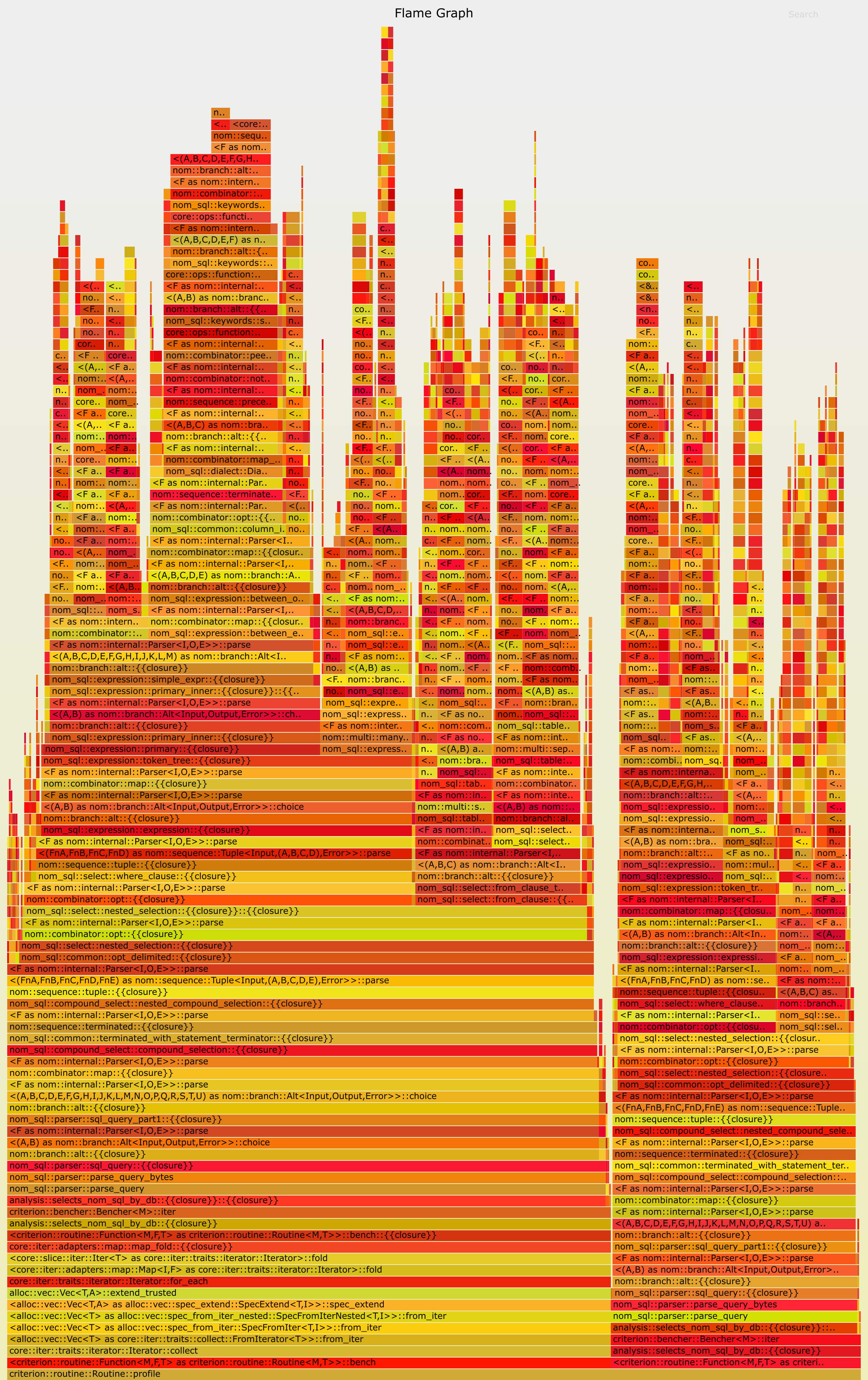
Don't see the problem? Well, that's probably because of the font size and truncation. Here is the original interactive SVG, but let me ask Claude to bust out the marker:
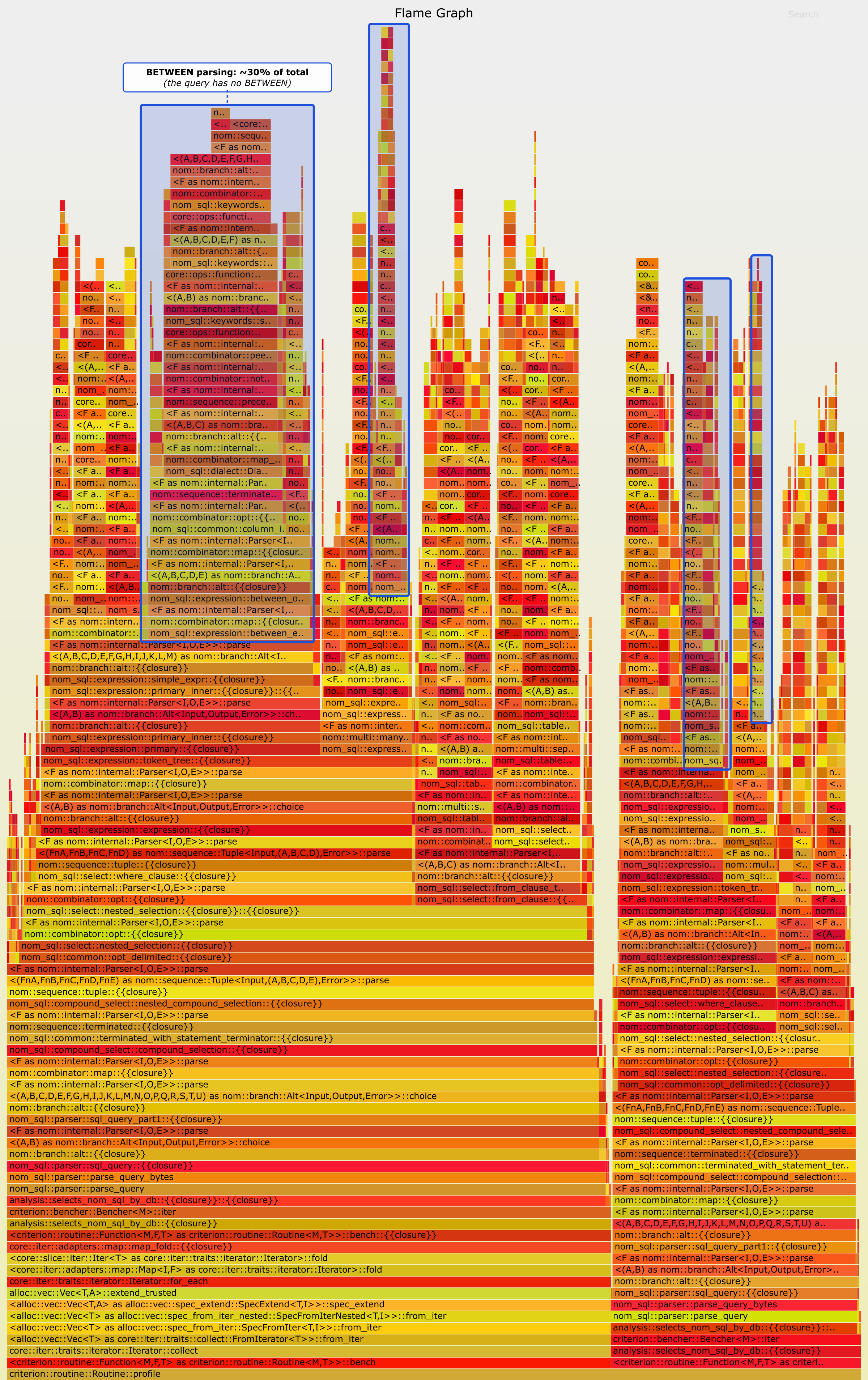
The blue boxes are everywhere that we attempt the between_expr subparser... and throw it away, because there is no BETWEEN in the query! This is the "work by failing" tax: ~30% of the time parsing this trivial query is spent in a (buggy) subparser that is irrelevant to the query, because we have to try every alt branch. And within that between_expr, we are trying a bunch of other subparsers parsing subsets of SQL expression syntax. It seems safe to assume 90% of the work we do in parsing is thrown away.
The microbenchmarks for sqlparser back that up too. I mentioned CASE ... WHEN is pretty complicated, and complicated tends to mean slow with parser combinators, so here's a comparison of 3 different parses of a query with that construct:
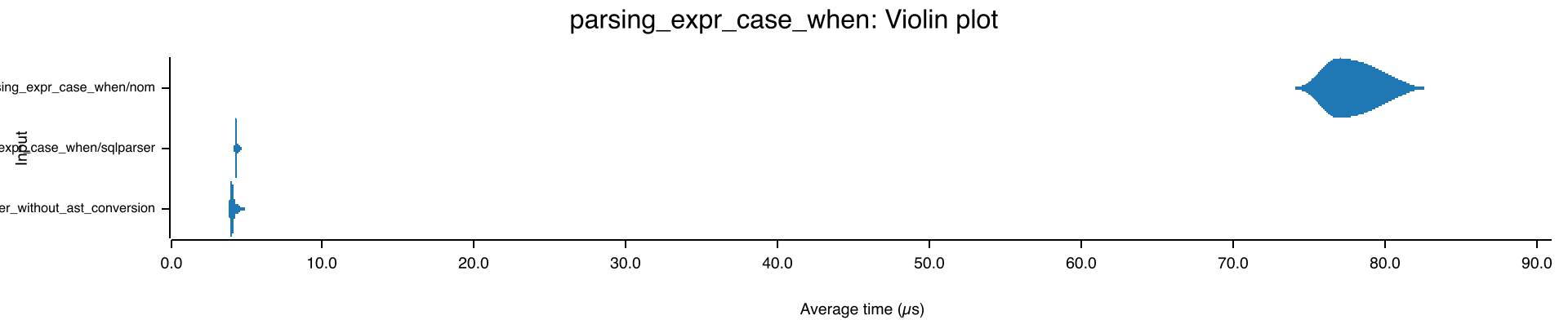
On top is nom-sql, ~78 µs. On the bottom is plain sqlparser, ~4.1 µs. So, 19x faster. Great, let's switch immediately. But what's that middle one that's ~4% slower than vanilla sqlparser?
Making the switch
We live in a society codebase, and our preexisting nom-sql AST types are, for better or worse, pretty pervasive throughout the system. For example, filter nodes in dataflow hold on to bits of AST to know how to calculate expressions (not great), we have a suite of SQL AST rewrites (unavoidable), and we have special methods for hashing the AST to decide which cache to route to (also unavoidable). It would be of questionable value to migrate all of those to sqlparser's AST. Additionally, we have customers relying on our existing parsing. sqlparser is great, a lot more comprehensive than nom-sql overall, but it does still have some coverage gaps. If a customer was using syntax sqlparser didn't support and we didn't know about it, and we switched parsing, they would have queries that previously got Readyset's signature 100x speedup suddenly routed to their upstream database, increasing upstream load and degrading downstream performance.
So how could we swap out parsing safely?

Our strategy had two parts:
- Keep our existing SQL AST, and convert to it from sqlparser's AST. This is the middle band in the violin plot above, showing ~4% overhead from conversion. If we ever want to adopt sqlparser's AST, we can do that work incrementally.
- Allow for parsing with both the old and the new parser, and diffing the results. This was invaluable in catching problems in our conversion routine, gaps in sqlparser's coverage, and uncovered some other bugs in nom-sql. And for an adjustment period, we have some customers running in this parse-with-both mode, accepting the performance overhead of the redundant parsing (but it's not really noticeably worse than just sticking with old nom-sql) to validate that they don't see any AST mismatches. New customers and those who've already validated their workloads can just switch to the new parser only and enjoy that speedup.
Summary
I don't have much in the way of summary, other than to say thank you to everyone involved in sqlparser, especially Ifeanyi Ubah who reviewed all our PRs to close the coverage gaps we needed for our customers. sqlparser has a bright future and Readyset looks forward to contributing more!
Related articles
Continue reading more about engineering.

Engineering Vassili Zarouba
Vassili Zarouba
How Readyset Rewrites Your SQL: Inside the Query Transformation Pipeline
Why Query Rewriting Matters for Dataflow Most databases work the same way: a query arrives, the engine builds an execution plan, scans tables, joins rows, filters, aggregates, and returns the result. Every time the query runs, the work repeats from scratch. This pull-based model has served relational databases for decades, but it carries an inherent cost: read latency is proportional to the complexity of the query and the size of the data it touches. Readyset takes a fundamentally different ap
Vassili Zarouba2026-04-28·17 min read

EngineeringMichael Victor Zink
/brutal-review and the new 80/20 rule
(Mistakes and em-dashes are my own.) We have a Claude Code command in our monorepo which is a good example of what I’m calling the "80/20 token rule": if it takes 20M LLM tokens to write a feature, you should spend 80M on ensuring quality: safety measures, testing, and of course code review. If software quality was an open problem before, then agentic engineering has blown it even more wide opener. At a high level, here's what it does: 1. Read the patch to review and all related code. 2. Ha
2026-02-03·22 min read

Engineering Mohamed Abdeen
Mohamed Abdeen
Readyset Adds New Query Capabilities With the Bucket Function
Readyset is a cache layer that sits between the application and the database, acting as a cache for supported queries and proxying unsupported queries upstream. This means that any query Readyset supports is theoretically supported by the upstream database, but not necessarily the other way around. What if that is no longer the case? What if Readyset can support queries that the upstream database can’t? What if you could keep your relational database and add extra functionality without any plug
Mohamed Abdeen2025-11-25·5 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.