← Back to blogDatabase Caching
Why Query Caching Is the Most Cost-Effective Way To Scale Databases — and Everyone’s Missing It
Scaling databases is no small task, and in the rush to find fast, affordable solutions, teams often overlook a key technique: query caching. By intelligently caching database queries, we’re sidestepping many of the typical challenges and costs that come with sharding, complex materialized views and resource-intensive indexes. Yet, it’s surprising how often query caching is dismissed as a solution. Let’s dive into why it might be the most cost-effective way to achieve the scale you’re after. Ho
Gautam Gopinadhan
2024-11-18 · 13 min read
Scaling databases is no small task, and in the rush to find fast, affordable solutions, teams often overlook a key technique: query caching. By intelligently caching database queries, we’re sidestepping many of the typical challenges and costs that come with sharding, complex materialized views and resource-intensive indexes. Yet, it’s surprising how often query caching is dismissed as a solution. Let’s dive into why it might be the most cost-effective way to achieve the scale you’re after.
How Are SELECT Queries Processed Under the Hood?
When a database receives a SELECT query, it follows a structured process to retrieve and format the requested data. Internally, this process involves multiple stages of parsing, planning, and executing, each aimed at making data retrieval as efficient as possible. Here’s an overview:
- Parsing, Analyzing and Planning: As soon as a query is issued, the database parses it to validate syntax and optimizes a query plan. This plan lays out the most efficient path to retrieve data by determining index usage, filtering, and join strategies.
- Execution: With the plan ready, the database’s execution engine retrieves data from disk storage or, if available, from memory (in the case of frequently accessed or “hot” data). It then assembles this data to match the query format, performing any necessary operations like scanning, sorting, and joining.
For large or complex datasets, these steps can be time-consuming. While databases are designed to optimize each phase, the repeated execution of identical queries—each requiring parsing, planning, and data retrieval—leads to considerable redundancy. Each time the same query is executed, the database repeats every step, consuming CPU, memory, and disk I/O resources—even when the data hasn’t changed.
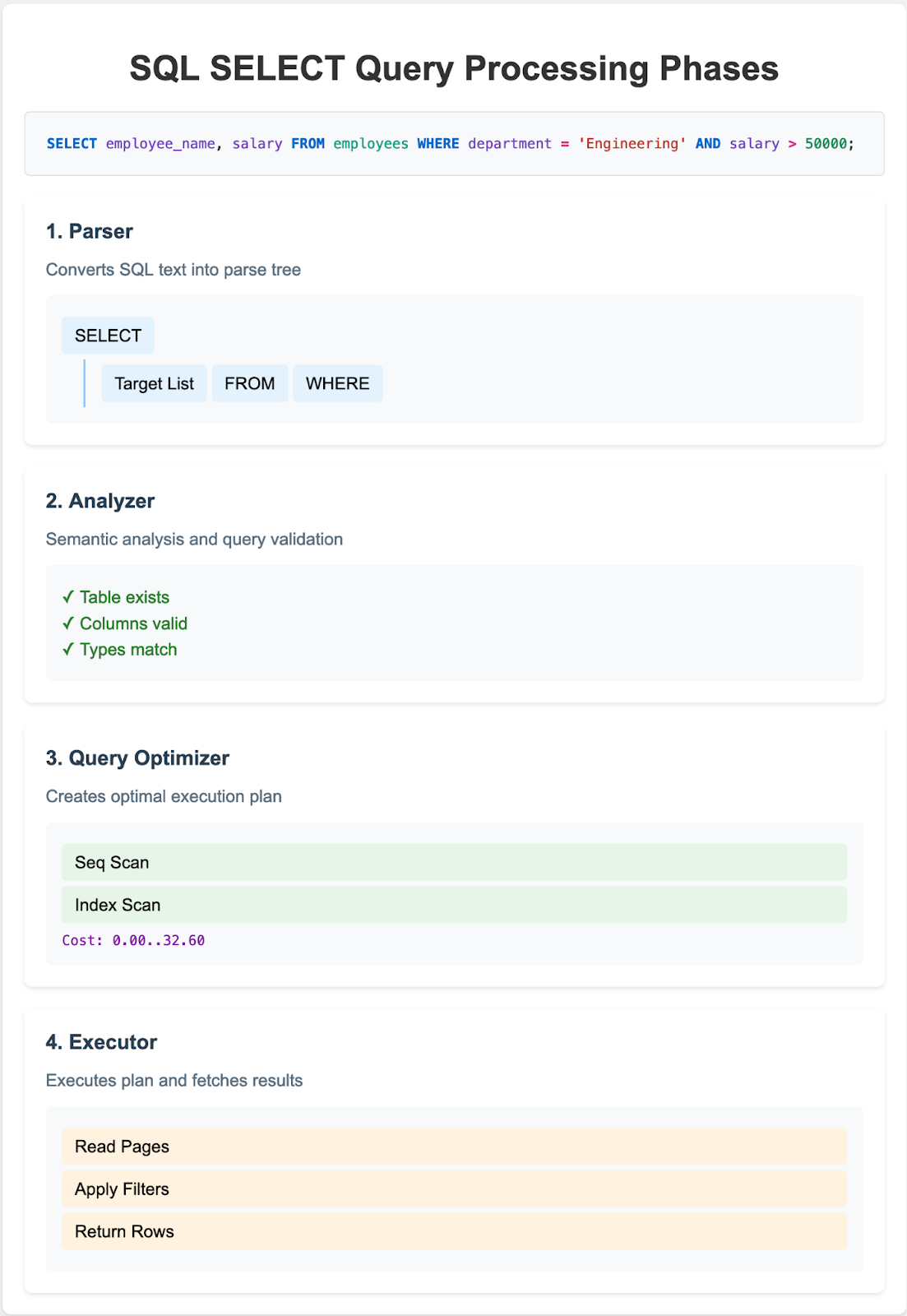
Fig 1. Typical phases when processing a SELECT Query.
In an ideal scenario, a caching solution would store and reuse query results for repeated queries, avoiding this redundancy. However, data is often subject to frequent updates, albeit typically at a lower rate than read requests. This presents a challenge: cache query results efficiently without serving outdated data.
By recognizing this disparity between read frequency and data change frequency, a well-designed caching layer can sidestep redundant query processing, serving cached results when possible and only recalculating when necessary. This is where query caching can offer significant performance gains over the standard approach.
What About Indexes?
Indexes are the standard go-to for speeding up query performance. Indexes and Analyzing and rewriting queries should be the first stop for improving performance. They allow the database to locate rows faster without scanning the entire table. Still, they may not suffice in many cases:
- Write Overheads: For every insert or update, the database has to update its indexes, which can slow down write-heavy applications.
- Memory Usage: Indexes consume memory and storage. Complex applications with numerous indexes can lead to memory bloat, impacting overall system efficiency.
- Diminishing Returns: For extremely complex or dynamic queries, indexes might offer only limited improvements, especially for non-primary key lookups or multiple joins.
- Performance: Even indexed queries are usually several times slower than purely cached workloads. A 2x - 5x performance boost from caching is still hugely advantageous on a well-indexed dataset.
But Databases Must Implement Caches Internally, Right?
Yes, databases typically implement a basic level of caching to avoid redundant I/O. They may use strategies like buffer pools or query result caches. However, these caches are often limited to single-node scope and don’t persist across sessions or application layers and most importantly do not provide good isolation. If newer workloads are introduced, they can easily trample on existing caches and cause universal slowdowns because of cache thrashing. They also tend to invalidate quickly, meaning frequent queries for high-demand applications still end up hitting the database repetitively. This approach doesn’t scale well across in highly dynamic, read-intensive applications.
Materialized Views and Their Shortcomings
Materialized views offer a way to store the results of a complex query for repeated use, essentially acting as a “snapshot” of data. But there are limitations:
- Maintenance Complexity: Materialized views must be periodically refreshed to stay current. In high-velocity environments, this often requires extensive infrastructure.
- Staleness: Materialized views can serve outdated data if not frequently refreshed, which is a problem in scenarios requiring real-time information.
- Overhead: The storage and compute resources for maintaining and refreshing materialized views add up, especially when scaling up.
- Query matching: Most databases do not automatically redirect a query to a materialized view, even if the query matches exactly with the view’s definition. PostgreSQL and MySQL treat the materialized view as a separate entity, and queries need to reference it by name to leverage its cached data explicitly. This adds overhead to application developers who often use ORMs to generate queries, and there is no easy way to map such queries to materialized view names. Referring to Materialized views as aliases makes them less transparent to application programmers.
Materialized views can be useful, but their limitations make them challenging for many scaling scenarios where data freshness and low-latency access are critical.
Sharding: The Cost of Distributed Complexity
When databases become too large or slow to handle, sharding—splitting data across multiple databases—is a typical strategy. However, it introduces new considerations:
- Application-Level Complexity: Sharding often requires application logic to determine which shard to query, which increases development complexity.
- Operational Overhead: Managing multiple shards requires robust monitoring, backups, and failover strategies.
- Cross-Shard Joins: If data relationships span shards, joins across shards can be resource-intensive and slow, complicating the entire database ecosystem.
- No latency improvement: Sharding only increases the ability of databases to scale out, but it does not bring down the latency of individual queries.
- Migration complexity: There is a lot of initial cost to migrating from your existing database to a sharded database solution. Customers must weigh the tradeoffs of migration and the operational and cost burden before making the move.
Caching with Redis and Memcached: Limited but Helpful
Redis and Memcached are popular for key-value caching outside the database. They’re great solutions for in-memory key-value lookups. Redis and Memcached have been repurposed for caching query results and can introduce their own pains:
- Cache Invalidation: Keeping the cache in sync with the database is tricky and often leads to stale reads.
- Memory Costs: Storing data in memory with Redis/Memcached is effective but can quickly become expensive at scale.
- Complexity of Caching Logic: Setting up effective cache strategies without bloating memory or creating inconsistency is not trivial, especially in high-scale environments.
- Application rewrites: Integrating a Redis or Memcached layer with your application often requires extensive rewrites of your application logic. Application authors must understand what to cache and how to manage these caches with TTLs and cache invalidation logic. Rewriting an application to make it work with Redis caching may make sense in certain situations. As a result, implementing application caching using Redis or Memcached usually requires several months of planning and effort.
Read Replicas and Their Shortcomings
One common approach to scaling read-heavy workloads is to set up read replicas—additional database instances that replicate data from the primary database in near-real-time. By distributing read queries across these replicas, the load on the primary database decreases, and response times improve as the workload is shared. However, while read replicas are widely used, they come with notable limitations:
- Increased Infrastructure Costs: Each read replica is a full copy of the primary database, requiring equivalent storage and compute resources. As the number of replicas grows, so do infrastructure costs, which can become substantial for applications with high data volumes or complex queries. Moreover, maintaining multiple replicas adds operational complexity, including monitoring, scaling, and backup management.
- Limited Scalability for Queries: While replicas can help distribute the load of read queries, they still place a considerable load on each replica, and if replicas aren’t optimized with appropriate indexes, the performance improvement may be minimal. Furthermore, the performance improvement of adding a read-replica is at most 1x the cost of the infrastructure. In other words, deploying two replicas will result in two times the performance of the original system; three replicas will deliver three times the performance, and so on. For webscale workloads, it is pretty standard to experience a 10x to 100x read spike at different times of the year (eg. Black Friday for a web storefront). Planning for such events using only Read Replicas can be onerous or extremely expensive.
- High Maintenance and Complexity: Maintaining read replicas introduces additional data synchronization, failover, and scaling configuration complexity. The more read-replicas you have, the more infrastructure elements you must manage. Ensuring all replicas remain consistent with the primary database requires diligent monitoring and often advanced configuration to handle edge cases such as replica failures or inconsistencies due to replication lag.
- Over-reliance on Database Scaling: While read replicas help distribute the load, they don’t eliminate redundant query processing as caching does. In many cases, a sophisticated caching solution can yield better performance gains by serving results from memory and reducing the need for repeated database hits.
In summary, while read replicas are useful for scaling reads, they are not a one-size-fits-all solution. They add cost and complexity and may not address performance challenges for applications. Query caching provides a more targeted solution by directly reducing the query load on the database without adding the operational and financial burdens that come with multiple replicas.
Why Readyset’s Query Caching Provides a More Scalable and Cost-Effective Solution
Readyset’s Smart Query Caching is built on a unique architecture that directly addresses performance and scalability issues inherent in traditional databases, offering a more efficient and cost-effective solution to scale read-heavy workloads. With Readyset, you’re not just adding yet another database replica or restructuring your data for sharding; instead, you’re adopting a system explicitly optimized for high-throughput, low-latency read performance.
Readyset’s Architecture: More than Just a Read Replica
Readyset operates as an independent layer that can be set up as a stand-in read replica or as a caching layer that selectively syncs with your primary database via WAL or binlog replication. This means Readyset can handle high-read workloads autonomously, processing and serving frequent queries independently of the primary database. With Readyset, only the most load-intensive queries must be offloaded, achieving response times up to 10x-100x faster than a typical database configuration. Because Readyset is a standalone cache that lives independently from the source database, you also have the option to deploy Readyset closer to the client, thereby working around even speed-of-light delays in database access with geo-located instances.
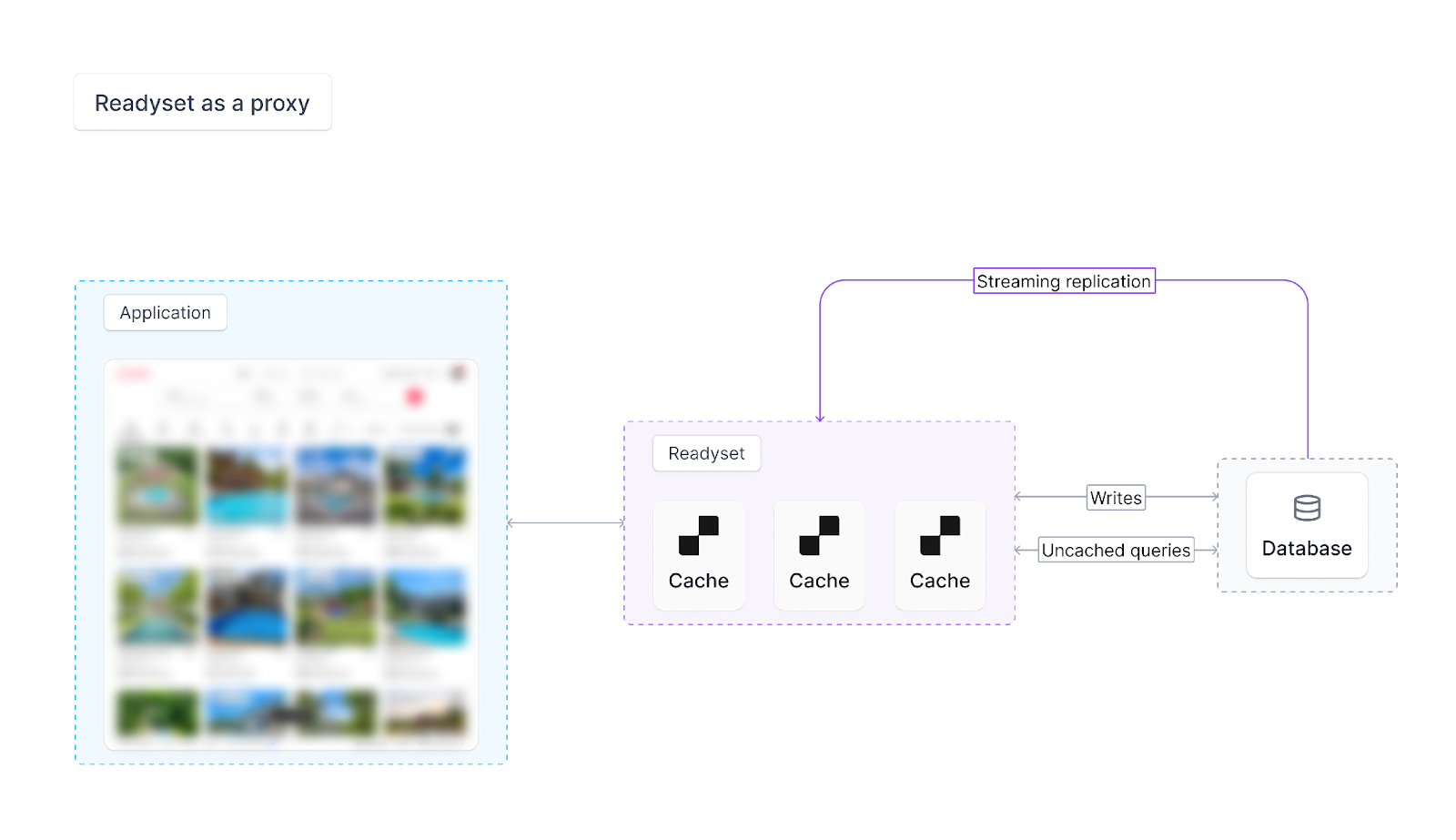
Fig 2. Readyset deployed as a proxy, intercepting all queries. Queries that are cached are serviced by Readyset, while all other queries are proxied through to the origin database.
Readyset integrates closely with industry-standard Query Routing software like ProxySQL, so existing systems already using ProxySQL can deploy Readyset into production with almost no effort.
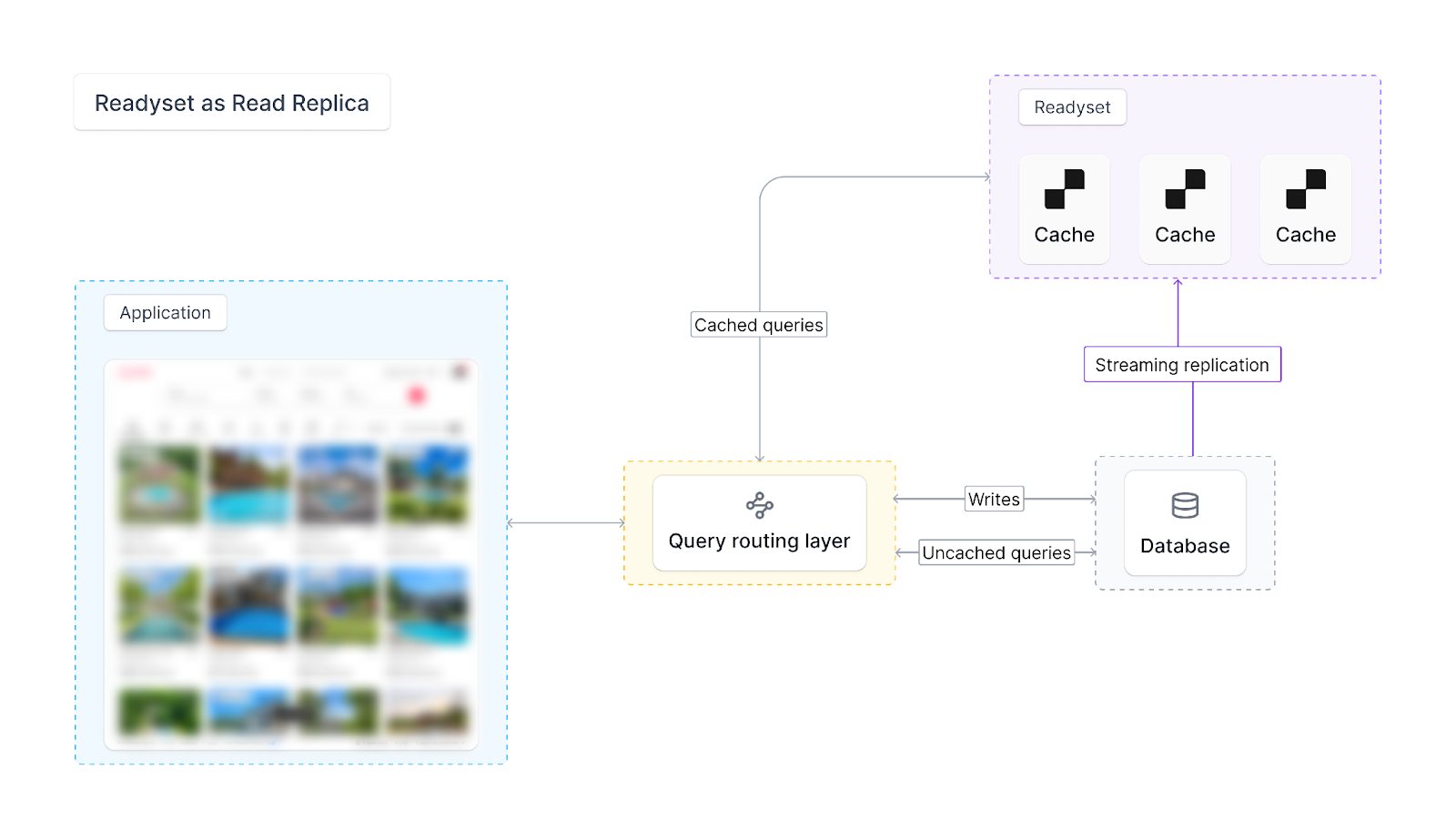
Fig 3. Readyset can be deployed with a query routing layer, like ProxySQL, akin to Read Replicas. Only selective queries can be forwarded to Readyset.
From a resource perspective, a single Readyset instance provides the equivalent throughput of multiple read replicas, significantly reducing the need for resource-hungry replicas to handle demand spikes.
Countering Common Database Scaling Shortfalls
- Efficient Query Processing without the Indexing Overhead: Unlike heavy indexing, which consumes storage and slows writes, Readyset’s query caching selectively stores only frequently accessed queries in memory, providing performance gains without the memory bloat or write overhead. This minimizes infrastructure costs while achieving significant read performance improvements.
- Isolation from Cache Thrashing: Internal database caching is often vulnerable to cache thrashing, where newer workloads overwrite existing cache entries, leading to slowdowns. Readyset, however, isolates these workloads by caching critical queries independently of the database’s buffer pool, ensuring stable, consistent performance without thrashing.
- Avoiding Sharding Complexity and Latency: Sharding distributes load but doesn’t address query latency, often increasing complexity and operational costs. Readyset, by caching high-demand queries, reduces the necessity of sharding and improves response times. By handling read throughput at significantly lower latency, Readyset eliminates much of the overhead and initial migration costs associated with sharding.
- Replacing Costly Read Replicas: Readyset reduces the need for numerous read replicas by delivering throughput equivalent to several replicas in a single instance. Traditional read replicas increase infrastructure and operational costs linearly. In contrast, Readyset scales reads exponentially by caching a small subset of frequently requested queries, making it far more cost-effective, especially during high-traffic periods.
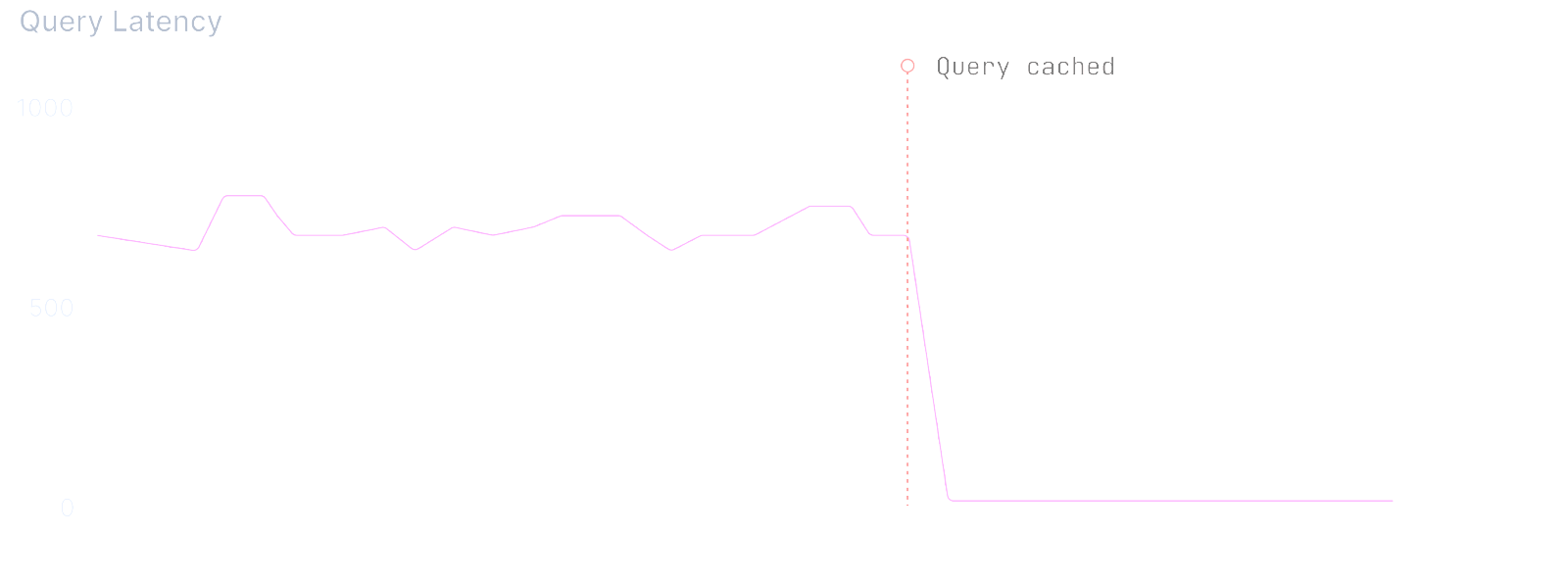
Fig 4. Readyset will dramatically cut query latency, often to the sub-millisecond range.
Dataflow Technology: Real-Time Caching and Minimal Overhead
At the core of Readyset’s architecture is Dataflow technology, an advanced approach that enables dynamic data dependency tracking and real-time cache updates:
- Real-Time Query Updates: When underlying data changes, Dataflow technology only updates the specific cached rows affected, preventing broad and costly refreshes. This keeps latency low, even with frequent data updates.
- Fine-Grained Dependency Management: Readyset tracks each query’s dependencies individually, updating only the relevant cached queries. This reduces memory use and maximizes processing efficiency, maintaining accurate, fresh query results without frequent full cache invalidations.
Partial Materialization: Caching Only What Matters
Readyset’s Partial Materialization offers a more targeted approach to caching than materialized views by caching only the high-demand keys within a query’s result:
- Reduced Memory and Storage Overhead: By only caching essential parts of a query, Readyset lowers memory and storage costs, even under high query volumes.
- On-Demand Data Retrieval: Readyset instantly serves common queries from the cache while still fetching non-cached data when necessary, making it versatile for applications with high-frequency and occasional queries.
- Targeted Refreshing: Partial Materialization enables Readyset to refresh only affected portions of cached data, minimizing compute requirements and accelerating response times for real-time use cases.
Cost-Effectiveness: Optimizing Performance without Infrastructure Bloat
Readyset’s unique approach makes it exceptionally cost-effective:
- Zipfian Distribution and Query Optimization: A small subset of queries often drives most of the load in typical databases. By caching this subset, Readyset capitalizes on the Zipfian distribution pattern, yielding up to 10x-100x improvements in latency and throughput for the queries that matter most.
- Minimized Storage and Memory Costs: Partial Materialization ensures only essential data is cached, significantly reducing memory and storage overhead compared to traditional materialized views or replicas.
- Scalability without Operational Complexity: Readyset’s caching layer offloads high read volumes with minimal infrastructure, allowing for efficient scalability without complex reconfiguration, making it a fit for environments with high read demands and controlled costs.
That’s great, but what's the catch with Query Caching?
Readyset’s Query Caching is an eventually consistent system similar to Read Replicas and in-memory caches. For applications requiring strict transactional consistency, such as those needing to “read your writes”, Query Caching may not be suitable as the latest writes are not guaranteed to be reflected in the cache. However, Readyset has a built-in mechanism to proxy these reads to the primary database when needed, ensuring the latest data is served in these infrequent cases.
With a focus on read-heavy workloads, Readyset is ideal for applications where high performance, scalability, and cost-efficiency are key. Readyset supports a wide range of SQL constructs, and queries generated by most applications will be supported by Readyset. Some complex SQL operations may not yet be fully supported, and we prioritize adding capabilities based on user feedback to ensure broad compatibility.
For most applications, Readyset delivers robust scalability without the complexities associated with sharding or additional caching infrastructure, making it a highly effective choice for scaling read-intensive workloads.
Conclusion
In the race to scale databases, companies often jump straight to complex, resource-intensive solutions like sharding, heavy indexing, or traditional caching systems, believing these are the only viable paths to handle surging read demands. But as we’ve explored, query caching—and specifically, Readyset’s unique approach with Smart Query Caching—offers an innovative and cost-effective alternative.
By leveraging Dataflow technology and Partial Materialization, Readyset doesn’t just cache data indiscriminately; it allows users to adapt to usage patterns intelligently, selectively caching and updating only what’s necessary. This approach sidesteps many of the typical bottlenecks that slow down traditional databases under high load. More than that, it’s a solution designed for real-world conditions where applications need fresh data, scalability, and low operational overhead.
In environments where high read performance is essential and costs must be contained, Readyset provides a clear path forward. Its architecture brings efficiency without requiring extensive infrastructure changes, integrating seamlessly into existing systems with zero code modifications. For teams looking to maximize database performance without sacrificing budget, Readyset’s query caching can unlock a level of scalability that might otherwise seem out of reach.
By rethinking how we approach caching and scaling, Readyset opens up a new realm of possibilities, making it a tool engineers and businesses should no longer overlook.
Related articles
Continue reading more about database caching.

Database Caching Vinicius Grippa
Vinicius Grippa
Readyset Internals: The left-right pattern: lock-free cache
How does Readyset serve cached reads without ever taking a lock? Explore the mechanics and real-world benchmarks of the left-right pattern and its 1.2-nanosecond atomic pointer swap.
Vinicius Grippa2026-07-01·8 min read

Database CachingVinicius Grippa
Caching real GitLab queries on Azure Postgres with Readyset
GitLab on Azure Postgres is expensive once a few teams start hammering the REST API. The bill grows because Postgres has to serve the same project list, issue count, and dashboard rollup over and over again, on top of the real work (writes, search, CI metadata). The standard answer is to scale up: For example, D4ds_v5 to D8ds_v5 to D16ds_v5, same shape, double the price (check the pricing calculator). This post walks through a different answer. We put Readyset between GitLab and an Azure Databa
Vinicius Grippa2026-05-11·8 min read

Database Caching Marcelo Altmann
Marcelo Altmann
Query Hints: Let Your Application Decide What Gets Cached
We kept hearing the same thing from customers: "We already know which queries need caching. Why do we need to go through the DBA to set it up?" Fair point. So we built Query Hints: The Old Way Was Slow for the Wrong Reasons Caching a query in Readyset used to require someone — usually a DBA or platform engineer — to connect to Readyset and run a CREATE CACHE statement. That works fine if you have a small, stable set of queries and an ops team with bandwidth. In practice, though, the bott
Marcelo Altmann2026-04-02·4 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.