Imagine you’re a developer for a large-scale e-commerce website that sells popular merchandise for sports teams (like my very own Golden State Warriors). One day, you receive an angry email that sales are lower than they ought to be, given your levels of website traffic. You’re losing money because excited customers are visiting your store but converting at a very low rate.
You decide to investigate and notice that your website is s-l-o-w. But rejoice! Your application has a read-heavy workload (displaying items to buy as customers browse your store) and skewed data access patterns (you show popular items repeatedly to many customers). These traits make your application a great candidate for a tried and true solution for improving performance: caching.
Why Caching for Database Performance Optimization?
Caching reduces the work your traditional database must do by moving frequently accessed records to an ultra-fast, in-memory database.
The problem is that a cache must be managed by the application that is using it. Your development team is now responsible for:
- Maintaining consistency - since your data is now stored in two different systems, developers must update the data in both the original database and the cache to avoid stale lookups.
- Changing query languages - caches use simple key-value lookups to access data, while your database likely uses SQL. Developers have to rewrite existing queries to work with your new cache.
- Handling eviction - if the cache gets full, your application needs to decide which records to kick out of the cache to make space. If you kick the wrong value out, the cache can thrash, wasting most of its time as it continually evicts hot values from the cache.
This makes caching difficult to implement correctly even for the best teams, leading to lots of outages like these.
In this blog, we’ll use our example e-commerce site to dive into exactly what it takes to start using a traditional caching system.
Options to Cache
Option 1: Rewriting a query to use a key-value store
Let’s assume you pick an in-memory database, like Redis, as your cache. Though blazingly fast, Redis doesn’t support SQL, so your application will need to switch to using its key-value interface.
You have two options to make your application work with your new cache:
- Rewrite individual queries to work with Redis’ key-value access patterns.
- Cache the results of entire SQL queries themselves in Redis.
Let’s first take a look at what goes into rewriting a single query to use a key-value interface. We'll use this example PRODUCTS schema for our store:
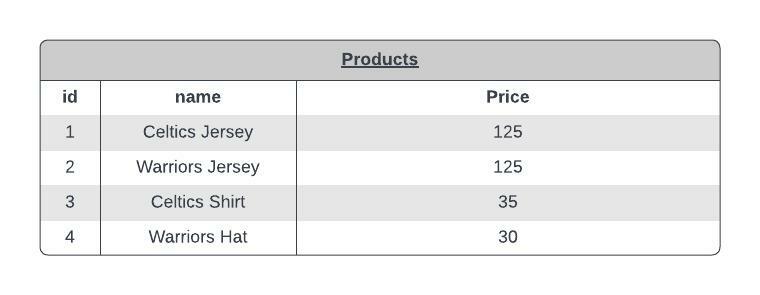
Since Redis can only store a single value for each key, we need to store the same value multiple times - with each “key” mapped to a different “value”. Here’s what a possible mapping between Redis tables and the original SQL tables in our application might look like - the product_list table for a {product_id: id} pairing, and a price_list table for a {price, product_id} pairing.
Using the same schema, here’s an example rewrite between SQL and Redis to query for all products with a price less than $150.
SQL Code:
Redis Code:
This returns a list of keys, e.g. product: 4. You then look up every item individually in the product_list table in Redis using their key and display that on your website.
While you’ve made each lookup of this specific query super fast, you’ve also had to completely re-write your product fetching code.
Let’s say this isn’t enough - your team needs to cache many queries, not all of which can easily be translated to Redis’ syntax. Instead, you decide to cache the results of each SQL query in Redis.
Option 2: Storing a complete SQL query in the cache
You come up with a simpler design for your caching logic. You store every unique application query as a key and the results for each query as the value associated with it in your cache.
Instead of running the query against your database every time, the application logic for fetching a page of items becomes:

Note that we’ve added the concept of staleness into the mix!
A cache key becomes stale when it sits longer than a timeout period, called a time-to-live (TTL) without being updated from the database. However, we can still read stale values if the database is updated before our TTL expires. In practice, choosing the right value for a TTL is a complex balance between refreshing too often (and overloading your database) and not refreshing often enough (and leaving stale values sitting for too long).
Despite the integration hassle, this simple model works well. Every time your users visit a page of items, the items are loaded straight from your cache. After a bit of time to warm up the cache, your cache hit ratio is almost 100% and you see page loads get faster and database load decrease.
Over time, the size and cost of your cache grow. Some keys (items) that were popular before are now rarely being accessed, making them good candidates for eviction.
You research different cache invalidation algorithms to help decide which keys to remove from the cache. While none of them are perfect, you implement one.
Unfortunately, saving valuable cache memory just opened the door to a few classes of subtle bugs.
Challenge #1: Filling the cache
A week later, disaster strikes.
After another amazing Steph Curry buzzer-beater, you run a promotion giving away free Golden State Warriors jerseys!
Fans are rushing to your site to buy his jerseys - but there’s a bug in your eviction strategy and you inadvertently evicted the object for his jersey from your cache. If all of your users hit your application while the cache is empty, each of your application instances will request the value from the cache, record a cache miss, and send their own request to the backing database.
This is known as a connection storm, where a thundering herd of connections bears down on your database all at once.
While databases without caching can suffer from connection storms, cached databases can have it particularly bad. Given that caching offloads a large number of reads, the backing database typically does not have enough capacity to handle the steady-state read load on the system - making it easy for your caches to try to fill themselves too aggressively, knocking the database offline.
In the worst case, a connection storm can continually overwhelm your database with a storm of new connections just as it comes back online, causing the database to fail repeatedly.
This highlights for your team the difficulty of getting your caching retry logic exactly correct.
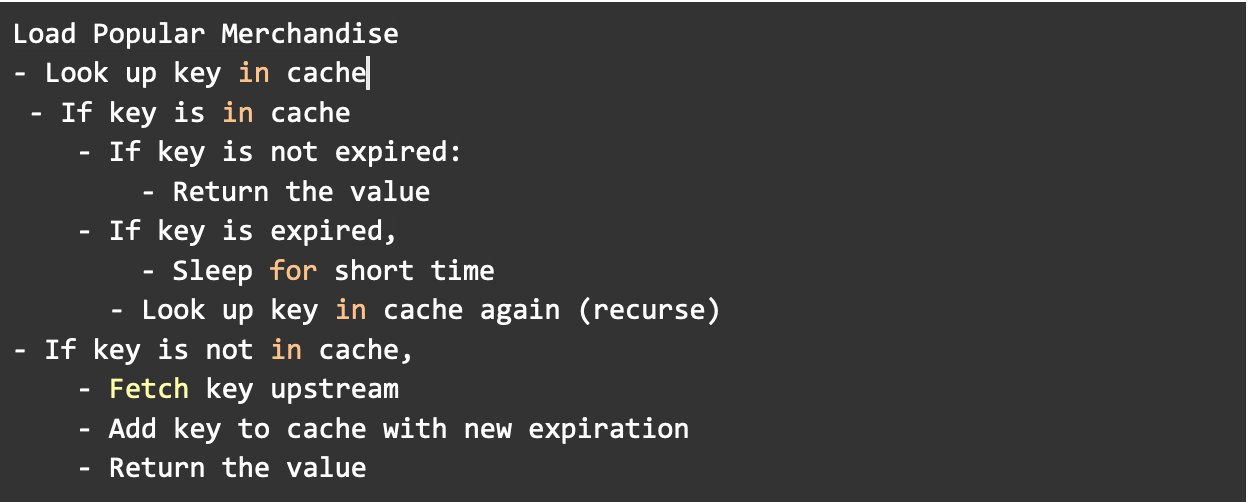
When doing a post-mortem on this incident, you discover that a common solution for a cache stampede is to add locking around the values in your cache. The end result isn’t significantly different from your existing logic, but it makes a large difference in performance. When modified, the logic above for the load items function becomes:
A new challenger approaches: dealing with stale data
Finally, the basketball playoffs are over - the Golden State Warriors are champions again! A new problem arises - Warriors fans have bought up all of Steph Curry’s jerseys and your store is completely out of stock. However, your website is still showing them as available when visitors are frantically refreshing the page and loading items. Your customers try to buy a new jersey and add it to their cart, only to see that it’s out of stock when they go to complete their purchase.
Your phone starts ringing off the hook - why can’t your users buy the jerseys your website claims to have??
The culprit is that your cache's data has become stale. Changes (writes) that are propagated to your underlying database (in this case, jersey purchases) are not being reflected in your cache immediately. Most caches wait until the value hits its TTL before checking back in for the up-to-date value in the database - and your TTL has been set to be too high.
To solve this, you lower your TTL to refresh the data more often... but this increases the load on your database! As discussed above, this is a nuanced balance between database load (from a low TTL) and stale data (from a high TTL). The longer data stays stale, the more likely users are to notice it in the application.
A happy(ish) ending: extending your caching layer and your new engineering workflow
Finally, you’re satisfied that your caching layer speeds up loading the items in your store without serving stale queries or knocking your database over.
A month later, you want to extend your cache’s functionality to new pages and categories - this means new queries to cache, new TTLs to optimize, and a whole lot of testing to do.
Your front-end development team rewrites the store’s category page logic to use your new cache. The application now has several different data access paths - some using an ORM to talk to your database, some using raw SQL to talk to the database, and some relying on the cache. Iterating on your application’s functionality requires coordinating across multiple teams and more complicated deployments to ensure nothing breaks.
You sell off your jersey store and retire to the Bahamas, never to think of caching again.
Epilogue
While we described some of the things that can go wrong with caching, the truth is that many small and mid-sized companies never even start the process of integrating a cache until they have a performance issue due to the associated complexity.
These companies don't ever see the performance or cost benefits a cache can make.
But the problems with caching aren’t just happening to small businesses. Caching failures have been responsible for massive real-world outages at large companies with entire teams dedicated to their caching
infrastructure, including at Facebook, Twitter, and Slack. For them, a more resilient caching architecture could prevent outages. These problems haven't changed much - caching was difficult back in the early 2000s, and it's still difficult today.
What if we could make database caching easier?
About Readyset: Performant SQL Caching Engine
Readyset is a SQL caching engine that helps you build performant, real-time applications without any code changes or switching databases. We're obsessed with making the cache we've always wanted as developers. Start caching queries today with Readyset Cloud, or self-host our open-source product, Readyset Core.
Authors