
← Back to blogDatabase Scaling
Vertical Scaling of MySQL vs. Horizontal Scaling with Readyset: A Cost and Performance Analysis in the Cloud
Scaling relational databases in the cloud often creates a tension between cost and performance. As workloads grow—especially read-heavy ones powering analytics, dashboards, or reports—latency increases and infrastructure bills spike. The default response is usually vertical scaling: increase instance size, add more CPU and memory. While effective up to a point, this approach quickly hits diminishing returns and inflates costs. An alternative is horizontal scaling, traditionally achieved through
Vinicius Grippa
2025-04-14 · 8 min read
Scaling relational databases in the cloud often creates a tension between cost and performance. As workloads grow—especially read-heavy ones powering analytics, dashboards, or reports—latency increases and infrastructure bills spike. The default response is usually vertical scaling: increase instance size, add more CPU and memory. While effective up to a point, this approach quickly hits diminishing returns and inflates costs.
An alternative is horizontal scaling, traditionally achieved through read replicas and query routing via tools like ProxySQL.
offers a different approach: a drop-in cache layer that intercepts and accelerates SQL queries without requiring changes to your application or schema. It works by transparently caching the results of supported SELECT queries and serving them from memory, improving throughput and reducing load on the primary database.
In this post, we’ll compare vertical and horizontal scaling using Readyset. We’ll measure cost and performance across three scenarios to help you decide where your infrastructure budget is best spent.
Real-World MySQL Architecture and Bottlenecks
In many production environments, a typical MySQL deployment includes one primary server and at least one read replica. This setup supports high availability and load distribution, particularly for backups, reporting, or read-heavy tasks. ProxySQL often sits in front of this setup, routing writes to the primary and reads to replicas.
If you’re interested in setting up ProxySQL with Readyset, Marcelo from Readyset wrote a practical guide on integrating the two.
Still, performance issues can surface even with replication and routing in place. A few complex queries, executed hundreds of times per day, can saturate your primary or replicas. So what’s the right move—add another replica? Scale up your instance size? Or do something smarter?
Benchmarking: Three Paths to Scaling MySQL
We used the Employees sample database and a set of 10 reporting-style SQL queries that simulate a realistic workload: joins, filtering, aggregations, and sorting. For benchmarking, we ran these queries in parallel with 200 concurrent connections using mysqlslap. We discarded the first test run in each case to avoid cold cache bias. The script and queries are available on GitHub.
We compared three approaches:
1. Baseline optimization using indexing
2. Vertical scaling (larger EC2 instance)
3. Horizontal scaling using Readyset
All tests were run on Percona Server 8.0.41-32.
Test 1 – Index Optimization on Baseline Instance
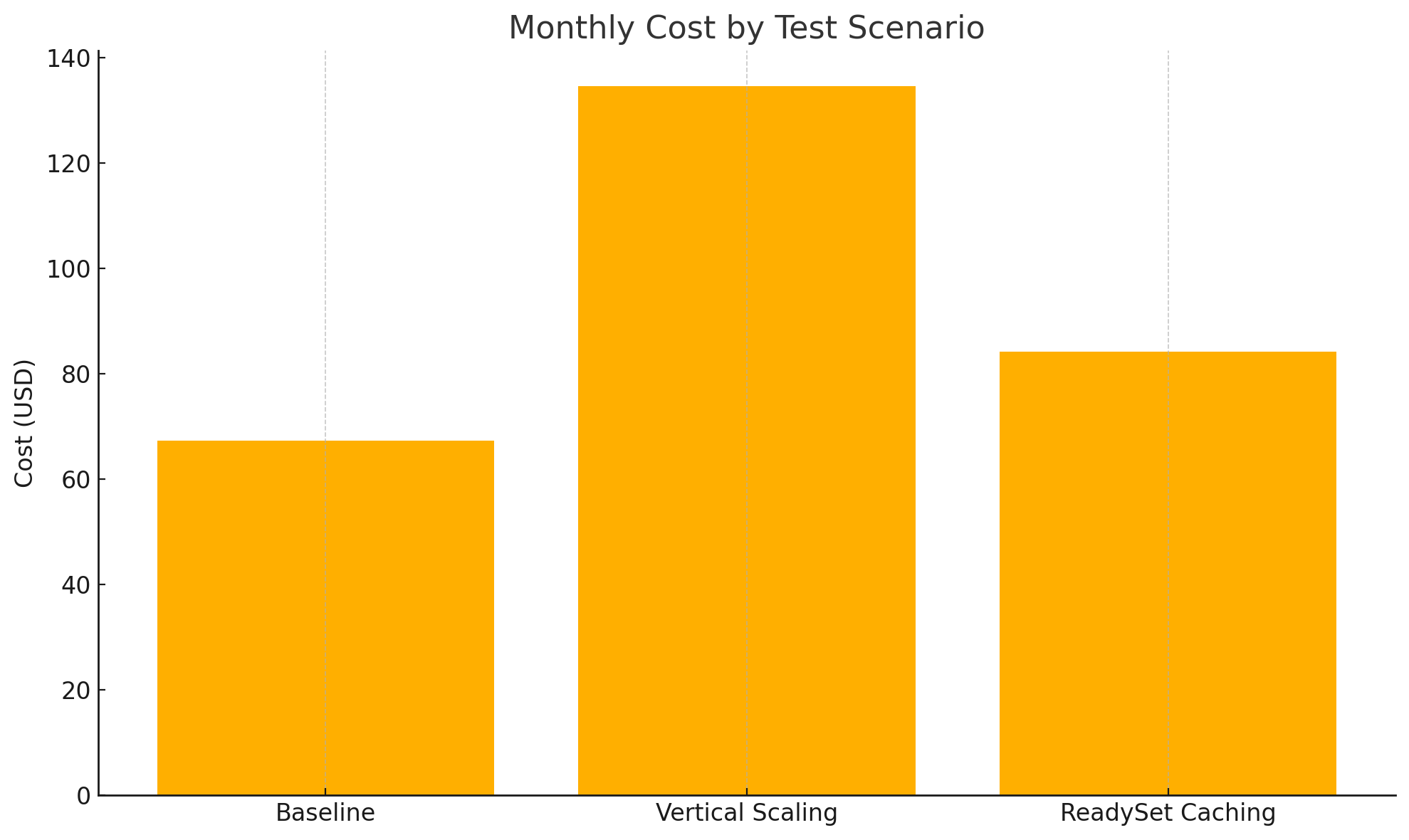
We began by benchmarking the workload on a standard t2.xlarge EC2 instance (4 vCPU, 16 GB RAM), which costs approximately $67.31 per month according to the AWS Pricing Calculator.
The first performance bottleneck was found in a query filtering employees based on a computed hire date:
SELECT emp_no, first_name, last_name, hire_date
FROM employees
WHERE hire_date > DATE_SUB('1995-01-01', INTERVAL FLOOR(RAND() * 3650) DAY)
ORDER BY hire_date ASC
LIMIT 10;
Execution Plan:
mysql> EXPLAIN SELECT emp_no, first_name, last_name, hire_date FROM employees WHERE hire_date > DATE_SUB('1995-01-01', INTERVAL FLOOR(RAND() * 3650) DAY) ORDER BY hire_date ASC LIMIT 10;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299157 | 33.33 | Using where; Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
The EXPLAIN plan showed a full table scan and filesort, with no index used.
The Fix:
An index was needed in the hire_date column to improve the efficiency of the WHERE condition.
CREATE INDEX idx_test1 ON employees(hire_date);
Result:
Before the index:
mysql> SELECT emp_no, first_name, last_name, hire_date FROM employees WHERE hire_date > DATE_SUB('1995-01-01', INTERVAL FLOOR(RAND() * 3650) DAY) ORDER BY hire_date ASC LIMIT 10;
76012b2365aaa53a9d0b21ea7d036059 -
10 rows in set (0.18 sec)
After adding the index:
mysql> SELECT emp_no, first_name, last_name, hire_date FROM employees WHERE hire_date > DATE_SUB('1995-01-01', INTERVAL FLOOR(RAND() * 3650) DAY) ORDER BY hire_date ASC LIMIT 10;
b8f7b252899bf00e3442b0c241a86be2 -
10 rows in set (0.00 sec)
After indexing, the query execution time dropped from 0.18 seconds to below 1 millisecond. MySQL reports it as 0.00 seconds by default, due to its two-decimal precision. A patch submitted by Marcelo (link) enables three-decimal-place output, confirming the query runs in the low-millisecond range.
Benchmark Results (t2.xlarge with indexing):
| Query | QPS |
|---|---|
| q1 | 177.62 |
| q2 | 180.67 |
| q3 | 183.66 |
| q4 | 7.29 |
| q5 | 165.70 |
| q6 | 183.15 |
| q7 | 5.13 |
| q8 | 7.12 |
| q9 | 5.01 |
| q10 | 6.42 |
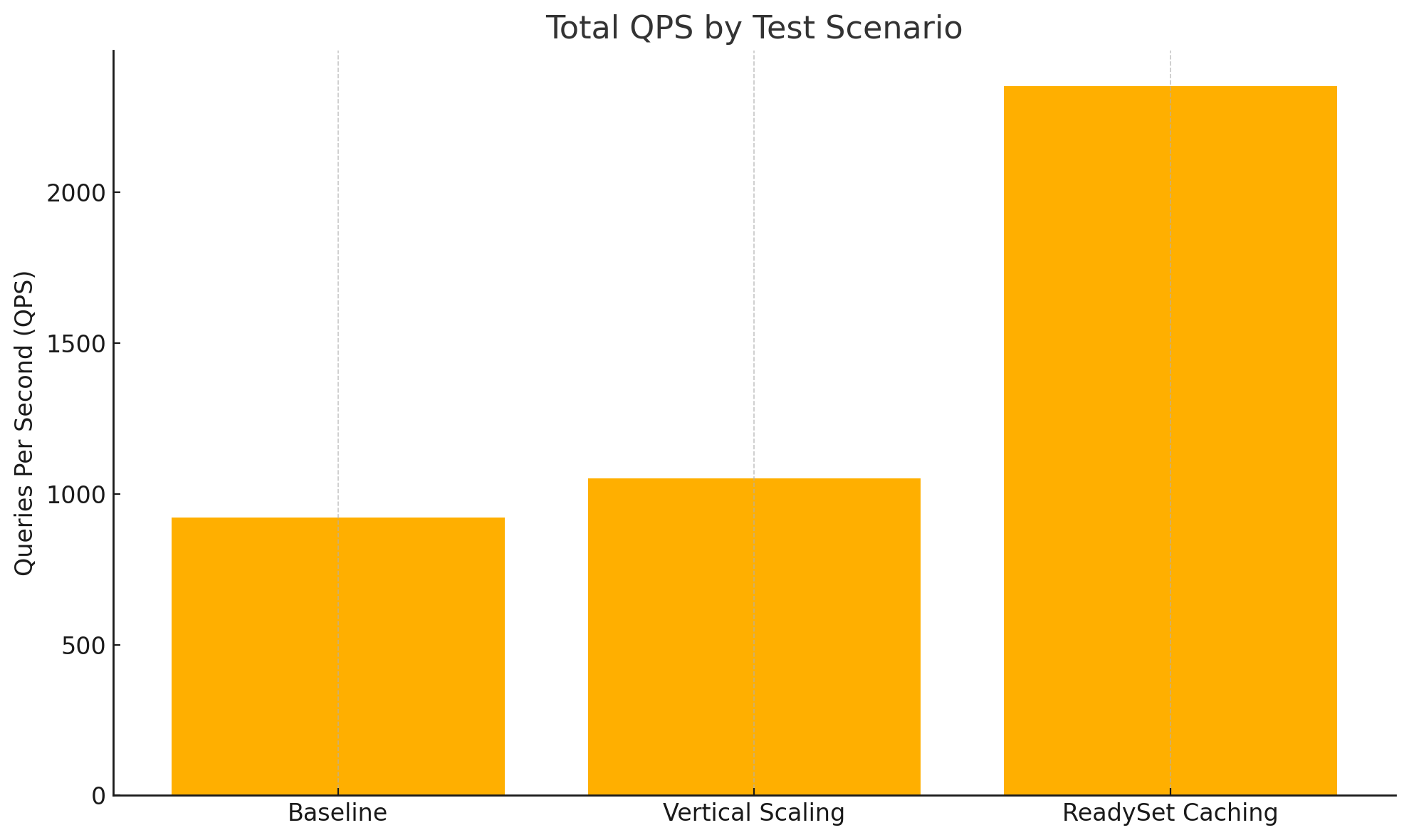
| Total | 921.77 QPS |
This test establishes the baseline and reinforces that proper indexing remains the most cost-effective performance optimization. Before scaling resources, query tuning should be the first step in addressing performance issues.
Test 2 – Vertical Scaling: Doubling Resources
Next, we upgraded the MySQL instance to a t2.2xlarge (8 vCPU, 32 GB RAM), doubling compute and memory. The estimated monthly cost is $134.61—twice that of the baseline.
To utilize the additional memory, we updated the MySQL configuration:
innodb_buffer_pool_size = 16G
innodb_redo_log_capacity = 8G
No changes were made to the application, queries, or indexing. The same benchmarking procedure was used: 10 concurrent queries over 200 total connections, warmed up before measurement.
Benchmark Results (t2.2xlarge):
| Query | QPS |
|---|---|
| q1 | 179.37 |
| q2 | 178.25 |
| q3 | 183.99 |
| q4 | 100.60 |
| q5 | 167.65 |
| q6 | 185.36 |
| q7 | 12.26 |
| q8 | 16.06 |
| q9 | 11.57 |
| q10 | 15.82 |
| Total | 1050.93 QPS |
This represents an approximate 14% performance improvement over the baseline. However, the cost doubled, resulting in a significantly lower return on investment compared to indexing alone. Vertical scaling is simple to implement but becomes increasingly inefficient as hardware costs rise faster than query throughput.
Test 3 – Horizontal Scaling with Readyset
In the third scenario, we returned to the baseline MySQL instance (t2.xlarge) and introduced Readyset on a separate t2.medium instance (2 vCPU, 4 GB RAM), costing approximately $16.86 per month. The total infrastructure cost in this setup was $84.17/month—still lower than the vertically scaled instance.
Readyset sits between the application and MySQL, intercepting supported SELECT queries and serving them from a high-performance cache. It integrates easily with ProxySQL or application-level routing and requires no changes to SQL logic or schema.
To prepare the cache, we used the SHOW PROXIED QUERIES command to verify which queries were supported:
readyset> SHOW PROXIED QUERIES;
+--------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------+
| query id | proxied query | readyset supported | count |
+--------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------+
| q_4b8c82487a56ba6c | SELECT `emp_no`, `first_name`, `last_name`, `hire_date` FROM `employees` WHERE (`hire_date` > $1) ORDER BY `hire_date` ASC | yes | 0 |
| q_bc605bf878f47842 | SELECT `e`.`emp_no`, `e`.`first_name`, `e`.`last_name`, `s`.`salary` FROM `employees` AS `e` JOIN `salaries` AS `s` ON (`e`.`emp_no` = `s`.`emp_no`) WHERE ((`e`.`emp_no` = $1) AND (`s`.`to_date` = $2)) | yes | 0 |
| q_9ecbc98d88c4d150 | SELECT DISTINCT `e`.`emp_no`, `e`.`first_name`, `e`.`last_name` FROM `employees` AS `e` JOIN `dept_manager` AS `dm` ON (`e`.`emp_no` = `dm`.`emp_no`) | yes | 0 |
| q_9652a1c8ff8e08c2 | SELECT `e`.`emp_no`, `e`.`first_name`, `e`.`last_name`, count(`t`.`title`) AS `total_titles` FROM `employees` AS `e` JOIN `titles` AS `t` ON (`e`.`emp_no` = `t`.`emp_no`) GROUP BY `e`.`emp_no`, `e`.`first_name`, `e`.`last_name` HAVING (`total_titles` > 1) ORDER BY `total_titles` DESC | yes
And then issued CREATE CACHE statements for each supported query ID:
readyset> CREATE CACHE FROM q_4b8c82487a56ba6c;
Benchmark Results (t2.xlarge + Readyset on t2.medium):
| Query | QPS |
|---|---|
| q1 | 49.95 |
| q2 | 421.05 |
| q3 | 422.83 |
| q4 | 11.38 |
| q5 | 275.86 |
| q6 | 424.63 |
| q7 | 8.44 |
| q8 | 306.75 |
| q9 | 422.83 |
| q10 | 10.02 |
| Total | 2353.74 QPS |
This setup achieved more than double the QPS of the vertically scaled configuration at a lower total cost.
The benefits were most pronounced on queries that were both supported by Readyset and frequently repeated.
It’s important to note that not all queries were cacheable. For instance, the following query was unsupported due to a straddled join, a pattern not currently supported by Readyset:
| q_53c06efa22ad2c29 | SELECT `e`.`emp_no`, `e`.`first_name`, `e`.`last_name`, `d`.`dept_name` FROM `employees` AS `e` JOIN `dept_emp` AS `de` ON (`e`.`emp_no` = `de`.`emp_no`) JOIN `departments` AS `d` ON (`de`.`dept_no` = `d`.`dept_no`) WHERE ((`d`.`dept_name` = $1) AND (`de`.`to_date` = $2)) | unsupported: Straddled joins are not supported | 0 |
Unsupported queries fall back to MySQL, so workloads with a high ratio of non-cacheable queries may see more limited performance gains.
Results and Analysis
The benchmark results show a clear distinction between the three approaches in terms of raw performance, cost, and overall efficiency.
1. Query Throughput (QPS):
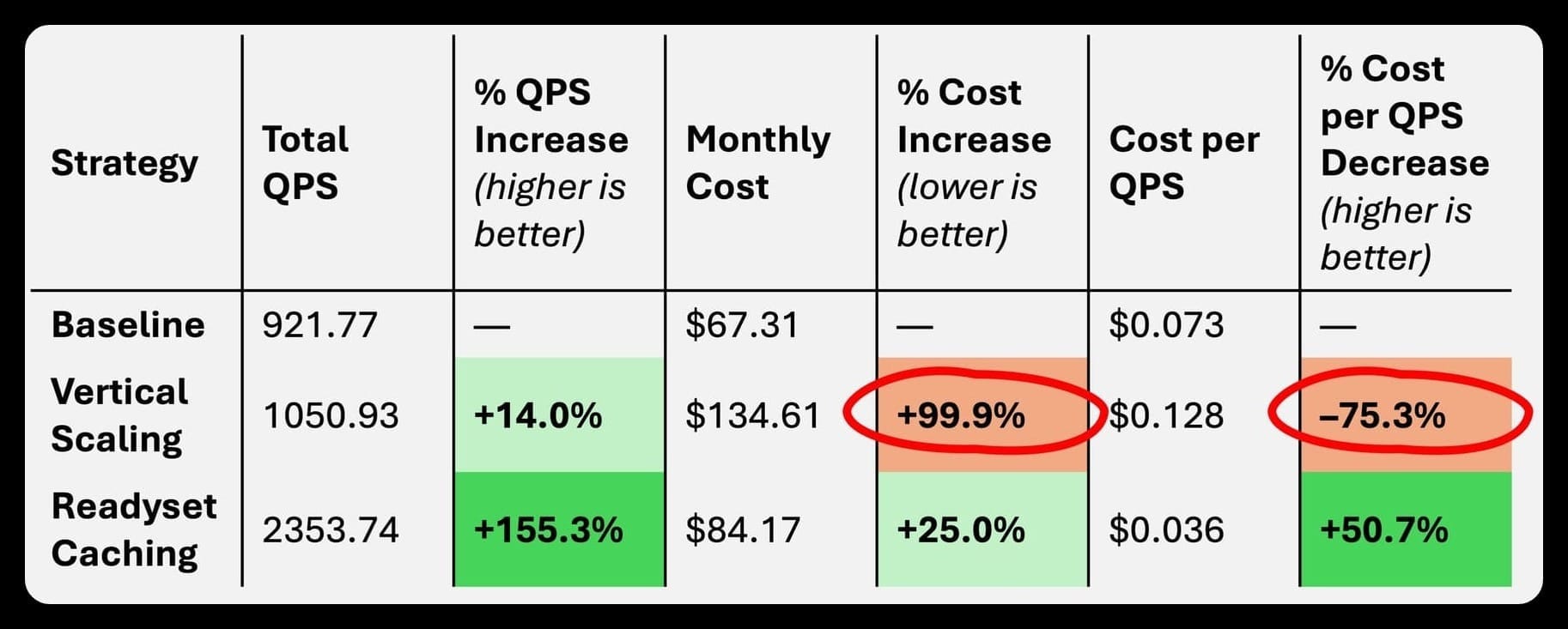
Readyset delivered the highest throughput by a wide margin, achieving 2.5x more QPS than vertical scaling and more than 2.5x the baseline performance with indexing alone. This reflects the impact of caching frequently accessed query results and offloading read pressure from MySQL.
2. Monthly Cost:
Vertical scaling incurred the highest cost, at $134.61/month, due to the doubled instance size. By contrast, the Readyset setup—combining a modest cache instance with the original MySQL instance—delivered far better performance at $84.17/month, which is 37% cheaper than vertical scaling. The baseline alone remained the lowest-cost option at $67.31/month, but with limited performance gains beyond the optimized queries.
3. Cost Efficiency (Cost per QPS):
When comparing cost relative to performance, Readyset clearly provided the best value. Its cost per QPS was ~$0.036, versus $0.128 for vertical scaling and $0.073 for indexing alone. This reinforces the value of caching and query distribution over simply scaling compute resources.
Summary
Conclusion
The results show that horizontal scaling is a strong option for predictable, read-heavy workloads. Indexing is a necessary first step—and it’s free—but its benefits level off quickly. Vertical scaling can help, but it comes with rising costs. Adding a smart caching layer offers better throughput and efficiency with minimal changes to your infrastructure.
This kind of caching doesn’t replace indexing or replication—it works with them. Indexes speed up individual queries; replicas distribute load. Caching accelerates repeated query patterns, making your system more scalable overall.
If you’re dealing with slow reads or rising cloud costs, Readyset can be a practical way to scale MySQL without rewriting your application.
Related articles
Continue reading more about database scaling.

Database ScalingVinicius Grippa
Caching Supabase with Readyset over IPv6: the AWS and Docker pieces that have to line up
Supabase's direct Postgres endpoint is IPv6-only, and a fresh AWS account has no IPv6 enabled. This walkthrough covers the exact VPC, subnet, and Docker configuration needed to run Readyset in front of Supabase on EC2, with three deployment paths: host network, dual-stack bridge, and Linux package.
2026-07-18·17 min read

Database Scaling Gautam Gopinadhan
Gautam Gopinadhan
The Hidden Complexity of Postgres Scaling Architectures
The OpenAI Postgres scaling article has been making the rounds, and for good reason. The piece does two things extremely well. First, it shows just how Postgres can be pushed far beyond what most teams assume is possible. Second, it makes clear that workloads at this scale don’t run on databases alone; they rely on caching, proxies, and careful query traffic management. It’s a rare public look at what it actually takes to run Postgres at serious scale. Why Scaling PostgreSQL at High Traffic
Gautam Gopinadhan2026-01-27·4 min read

Database Scaling Tanmay Sinha
Tanmay Sinha
Does Your Black Friday Database Scaling Strategy Involve Duct Tape and Prayers?
It Might Be Time to Rethink How You Scale MySQL for Peak Demand As Black Friday and Cyber Monday approach, many engineering teams prepare for their annual database performance stress test. The surging traffic, unpredictable spikes, and sleepless nights spent watching database dashboards. The typical response is familiar: add more replicas, increase compute resources, and pray everything holds. But this approach to database scaling is reactive, costly, and fragile. What begins as a quick fix be
Tanmay Sinha2025-10-21·4 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.