← Back to blogMySQL
Replication Internals: Decoding the MySQL Binary Log Part 11: GTID_TAGGED_LOG_EVENT — Tagged GTIDs and MySQL's New Serialization Framework
In this eleventh and final post of our series, we decode the GTID_TAGGED_LOG_EVENT — the event MySQL 8.4 introduced to carry user-defined tags alongside the classic UUID and GNO, and along the way meet the new mysql::serialization framework that encodes it. Introduction Back in Part 5 we deferred one event: the GTID_TAGGED_LOG_EVENT (event type 42, 0x2a). It was introduced in MySQL 8.4 to support tagged GTIDs, which extend the classic UUID:GNO form with an optional user-defined label: 557789
Marcelo Altmann
2026-05-13 · 21 min read
In this eleventh and final post of our series, we decode the GTID_TAGGED_LOG_EVENT — the event MySQL 8.4 introduced to carry user-defined tags alongside the classic UUID and GNO, and along the way meet the new mysql::serialization framework that encodes it.
Introduction
Back in Part 5 we deferred one event: the GTID_TAGGED_LOG_EVENT (event type 42, 0x2a). It was introduced in MySQL 8.4 to support tagged GTIDs, which extend the classic UUID:GNO form with an optional user-defined label:
55778904-0299-11f1-b1b8-4ef0c4956feb:mytag:3
└────────── SID (UUID) ───────────┘ └tag┘ └GNO
A tag is [a-z_][a-z0-9_]{0,31} — up to 32 lowercase characters. Two transactions that originate on the same server but carry different tags occupy independent GNO sequences: the server can have …:mytag:1-100 and …:other:1-50 at the same time, with no collision. That makes tagged GTIDs useful for multi-source replication and for separating administrative work from application traffic.
The on-disk format is also completely different from the untagged GTID_LOG_EVENT we decoded in Part 5. Instead of a fixed 42-byte post-header followed by a few packed integers, the entire payload is produced by MySQL's new mysql::serialization library — a forward-/backward-compatible TLV encoding using variable-length integers and explicit field IDs. We'll spend most of this post on that encoding, because once it clicks, every byte in the event falls into place.
For this post we'll use a different file from the rest of the series: binlog_gtid_tag.000001, generated against MySQL 9.6.0 with one tagged transaction. It contains the same kinds of events we've already covered — magic number, FORMAT_DESCRIPTION_EVENT, PREVIOUS_GTIDS_LOG_EVENT, a TABLE_MAP/WRITE_ROWS pair, an XID_EVENT, and a closing ROTATE_EVENT — except the GTID at position 245 is a GTID_TAGGED_LOG_EVENT instead of the classic GTID_LOG_EVENT.
Event Location
Position 245: GTID_TAGGED_LOG_EVENT (83 bytes) ← Our subject
Position 328: QUERY_EVENT - BEGIN
Position 405: TABLE_MAP_EVENT
Position 461: WRITE_ROWS_EVENT
Position 510: XID_EVENT
Position 541: ROTATE_EVENT
Position 585: (end of file)
The transaction wrapped by this event is a single-row INSERT into test.orders, executed under SET GTID_NEXT = '55778904-...:mytag:3'.
Reading the Raw Bytes
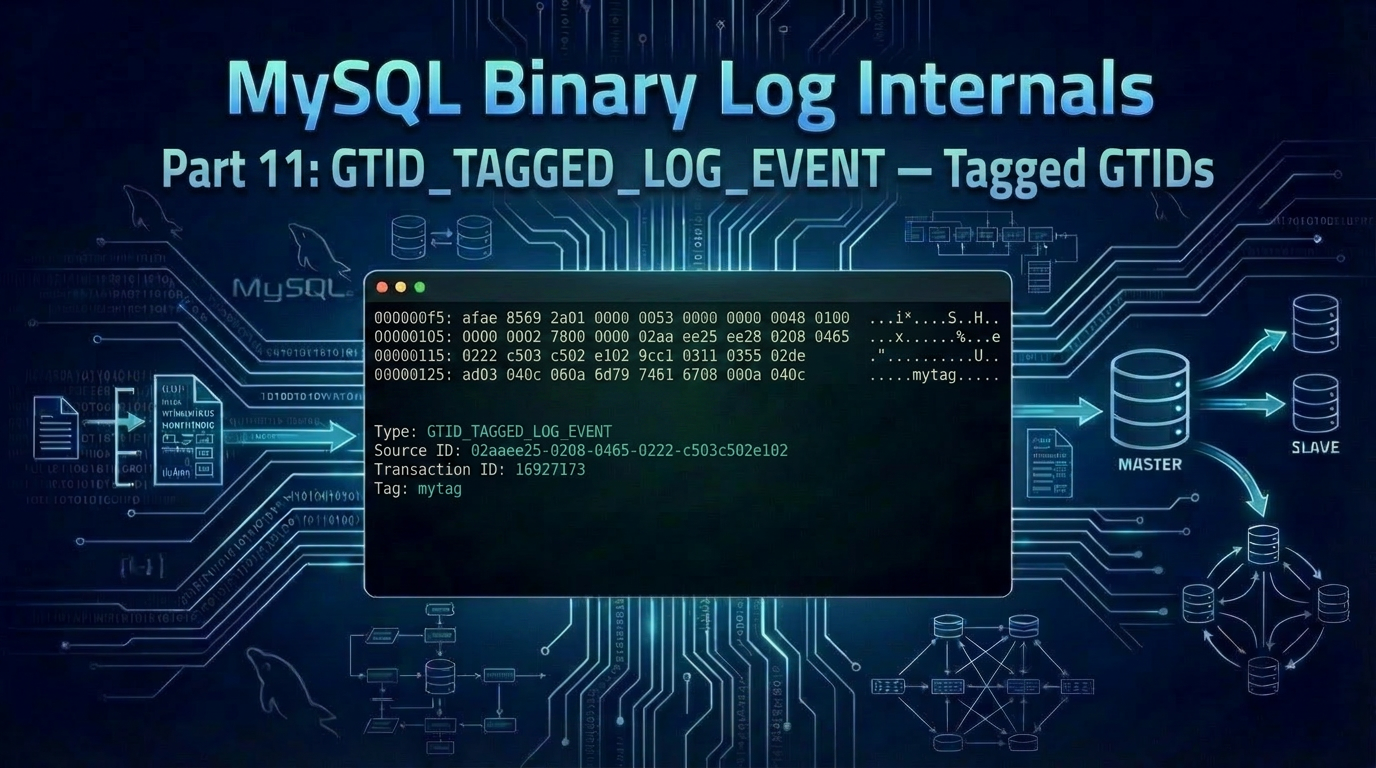
$ xxd -s 245 -l 83 binlog_gtid_tag.000001
000000f5: afae 8569 2a01 0000 0053 0000 0048 0100 ...i*....S...H..
00000105: 0000 0002 7800 0000 02aa ee25 0208 0465 ....x......%...e
00000115: 0222 c503 c502 e102 9cc1 0311 0355 02de ."...........U..
00000125: ad03 040c 060a 6d79 7461 6708 000a 040c ......mytag.....
00000135: 7f1c f3b8 1424 4a06 10a1 0412 430f 0b78 .....$J.....C..x
00000145: 72ad 08 r..
The event is 83 bytes: 19-byte common header + 60-byte serialized payload + 4-byte checksum. Notice the ASCII mytag in the middle of the dump — the only part of the event readable without a decoder.
Common Header (19 bytes)
afae8569 2a 01000000 53000000 48010000 0000
│ │ │ │ │ │
│ │ │ │ │ └─→ Flags: 0x0000
│ │ │ │ └───────────→ Next Position: 328
│ │ │ └────────────────────→ Event Size: 83 bytes
│ │ └─────────────────────────────→ Server ID: 1
│ └────────────────────────────────→ Event Type: 42 (GTID_TAGGED_LOG_EVENT)
└─────────────────────────────────────────→ Timestamp: 1770368687
| Field | Bytes | Little-Endian | Value |
|---|---|---|---|
| Timestamp | afae8569 | 0x698585af | 1770368687 (2026-02-06 06:04:47) |
| Event Type | 2a | 0x2a | 42 (GTID_TAGGED_LOG_EVENT) |
| Server ID | 01000000 | 0x00000001 | 1 |
| Event Size | 53000000 | 0x00000053 | 83 bytes |
| Next Position | 48010000 | 0x00000148 | 328 |
| Flags | 0000 | 0x0000 | No flags |
The event type code 42 (0x2a) is the discriminator that tells the reader to take the new code path. It is defined alongside GTID_LOG_EVENT = 33 in Log_event_type, and the dispatch happens inside the shared Gtid_event constructor:
if (header()->type_code == GTID_TAGGED_LOG_EVENT) {
auto data_event_len = header()->data_written - fde->common_header_len;
if (footer()->checksum_alg != BINLOG_CHECKSUM_ALG_OFF) {
data_event_len -= BINLOG_CHECKSUM_LEN;
}
read_gtid_tagged_log_event(buf + fde->common_header_len, data_event_len);
BAPI_VOID_RETURN;
}
read_gtid_tagged_log_event() hands the payload to a Decoder_type (mysql::serialization::Serializer_default<Read_archive_binary>) and lets the framework do the work — there is no hand-rolled byte parser for this event.
A New Serialization Framework
Everything we decoded in Parts 2–10 used MySQL's classic event format: fixed-width fields, a few packed integers, byte offsets baked into the spec. GTID_TAGGED_LOG_EVENT breaks with that convention. The same Gtid_event C++ class produces both wire formats, but for the tagged variant the fields are routed through the mysql::serialization library, declared on the class itself via define_fields():
decltype(auto) define_fields() {
return std::make_tuple(
mysql::serialization::define_field(gtid_flags),
mysql::serialization::define_field_with_size<Uuid::BYTE_LENGTH>(
tsid_parent_struct.get_uuid().bytes),
mysql::serialization::define_field(gtid_info_struct.rpl_gtid_gno),
mysql::serialization::define_field_with_size<mysql::gtid::tag_max_length>(
tsid_parent_struct.get_tag_ref().get_data()),
mysql::serialization::define_field(last_committed),
mysql::serialization::define_field(sequence_number),
mysql::serialization::define_field(immediate_commit_timestamp),
mysql::serialization::define_field(original_commit_timestamp,
Field_missing_functor([this]() -> auto{
this->original_commit_timestamp = this->immediate_commit_timestamp;
})),
mysql::serialization::define_field(transaction_length),
mysql::serialization::define_field(immediate_server_version),
mysql::serialization::define_field(original_server_version, ...),
mysql::serialization::define_field(commit_group_ticket, ...));
}
Three properties of this library matter for decoding:
- Every field is preceded by a numeric field ID. Fields are numbered
0..Nin tuple order and are written as TLV (tag-length-value, with the length implicit in the type). Decoders that don't recognize a field can skip it. - Optional fields can be omitted entirely.
original_commit_timestamp,original_server_version, andcommit_group_ticketcome with predicates that suppress encoding when the value is "default" (equal to the immediate value, or zero). On the wire, the next field's ID simply jumps ahead — there's no placeholder byte. - Integers are variable-length. Both the field IDs and most of the values use the same unary-prefix varint encoding (we'll decode it byte by byte in the next section). This is what makes the whole 60-byte payload smaller than the 56-byte fixed payload of the untagged GTID — at least for small values.
The "framework" wrapper produces three header bytes before any field, written by encode_serializable_metadata():
m_archive << create_varlen_field_wrapper(field_id); // format version
m_archive << create_varlen_field_wrapper(encoded_size); // total size
m_archive << create_varlen_field_wrapper(last_non_ignorable_field_id);
So the very first three varints of every event encoded with this library are: the serialization format version (currently 1), the total encoded size, and the highest field ID that an old reader is not allowed to skip (zero when every field is marked ignorable — which is the default for Gtid_event).
The Variable-Length Integer Encoding
Before we touch the payload we need one primitive: the unsigned varint. From variable_length_integers.h:
The first byte's count of trailing 1-bits (call it k) tells the reader how many total bytes the integer occupies:
total = k + 1. The high(8 - total)bits of byte 0, followed by the remaining(total - 1)little-endian bytes shifted into the upper positions, hold the value.
In code, the decoder is essentially:
uint8_t first = stream[0];
size_t num_bytes = std::countr_one(first) + 1;
uint64_t value = first >> num_bytes;
if (num_bytes > 1) {
uint64_t tail = 0;
memcpy(&tail, &stream[1], num_bytes - 1);
tail = le64toh(tail);
value |= tail << (8 - num_bytes + ((num_bytes + 7) >> 4));
}
A few worked examples (we'll see all of these in the payload):
| First byte | Binary | trailing-1s | num_bytes | Value |
|---|---|---|---|---|
| 0x02 | 00000010 | 0 | 1 | 0x02 >> 1 = 1 |
| 0x78 | 01111000 | 0 | 1 | 0x78 >> 1 = 60 |
| 0xaa | 10101010 | 0 | 1 | 0xaa >> 1 = 85 (0x55) |
| 0x25 02 | 00100101 … | 1 | 2 | (0x25 >> 2) | (0x02 << 6) = 137 (0x89) |
| 0x7f 1c f3 b8 14 24 4a 06 | 01111111 … | 7 | 8 | 0x064a2414b8f31c = 1770368687207196 |
Two encoding notes:
- Signed integers use zigzag encoding on top of the unsigned varint: write
(value << 1) ^ (value >> 63), decode by reversing it. Solast_committed = 0becomes0x00,sequence_number = 1becomes0x04,-1would be0x02. The signed wrapper is automatic — it's chosen based on the C++ type. std::array<unsigned char, N>(used for the SID/UUID) is not copied as raw bytes. The serializer iterates over the array and encodes eachunsigned charas a varint — so high-bit-set bytes consume two bytes on the wire, and a 16-byte UUID can be anywhere from 16 to 32 bytes depending on its value. Our UUID encodes to 25 bytes.
That last point surprised us, too. Keep it in mind: there's nothing magic about the UUID being 16 bytes on disk — it isn't.
Payload Structure
With the encoding pinned down, here's the field layout of the 60-byte payload, in the order it appears on the wire. Field IDs are assigned by define_fields() (tuple position, 0-indexed):
| # | Field ID | Field | C++ type | On-wire form | Notes |
|---|---|---|---|---|---|
| — | — | format_version | uint8 | varint | Always 1 |
| — | — | encoded_size | uint64 | varint | Total payload size (this metadata included) |
| — | — | last_non_ignorable_field_id | uint64 | varint | 0 — every Gtid_event field is ignorable |
| 1 | 0 | gtid_flags | uint8 | varint | Same FLAG_MAY_HAVE_SBR bit (0x01) as the untagged event |
| 2 | 1 | SID | std::array<uint8_t, 16> | 16 varints | The server UUID, byte by byte |
| 3 | 2 | GNO | int64 | signed varint | Group number within (SID, tag) |
| 4 | 3 | Tag | std::string (≤32 ASCII chars) | varint length + raw bytes | Empty string for an untagged GTID written in tagged format |
| 5 | 4 | last_committed | int64 | signed varint | Parallel-replication parent |
| 6 | 5 | sequence_number | int64 | signed varint | Parallel-replication timestamp |
| 7 | 6 | immediate_commit_timestamp | uint64 | varint | µs since epoch on the immediate server |
| 8 | 7 | original_commit_timestamp | uint64 | varint | Omitted when equal to immediate |
| 9 | 8 | transaction_length | uint64 | varint | Total transaction size in bytes |
| 10 | 9 | immediate_server_version | uint32 | varint | e.g. 90600 = MySQL 9.6.0 |
| 11 | 10 | original_server_version | uint32 | varint | Omitted when equal to immediate |
| 12 | 11 | commit_group_ticket | uint64 | varint | Omitted when 0 (no BGC ticket) |
Three big differences from the untagged GTID payload of Part 5 are worth calling out before we decode:
- There is no
logical_clock_typecodebyte. The framework's field-id metadata makes typecodes redundant. - The commit timestamps are unsigned varints, not fixed 7-byte
int7store. The "MSB of byte 6 indicates whether an original timestamp follows" trick from Part 5 is gone; instead, presence is signalled by field ID 7 appearing (or not) on the wire. - The server versions are unsigned varints, not fixed 4-byte
int4store. Again, the high-bit trick is replaced by an explicit field ID.
Field-by-Field Decoding
Here are the 60 payload bytes split by field:
02 78 00 ← framework header (format=1, encoded_size=60, last_non_ignorable=0)
00 00 ← #1 gtid_flags = 0
01 aa ee 25 02 08 04 65 02 22 c5 03 c5 02 e1 02 9c c1 03 11 03 55 02 de ad 03
← #2 SID = 55778904-0299-11f1-b1b8-4ef0c4956feb (25 bytes on the wire)
04 0c ← #3 GNO = 3
06 0a 6d 79 74 61 67← #4 Tag = "mytag" (length=5)
08 00 ← #5 last_committed = 0
0a 04 ← #6 sequence_number = 1
0c 7f 1c f3 b8 14 24 4a 06
← #7 immediate_commit_timestamp = 1770368687207196 µs
10 a1 04 ← (jumps from id=6 to id=8 — original_commit_timestamp absent)
#9 transaction_length = 296
12 43 0f 0b ← #10 immediate_server_version = 90600
(no field id 10 or 11 follow — both optional fields absent)
Let's walk it.
Framework header — 02 78 00
0x02→ varint = 1 → serialization format version 1. From serialization_format_version.h, this is the only value currently defined.0x78→ varint = 60 → encoded size of this whole serializable (the full 60-byte payload). Decoders use this to know where the event ends without relying on the common header'sevent_size.0x00→ varint = 0 → last non-ignorable field ID. EveryGtid_eventfield carries the default policyUnknown_field_policy::ignore(field_definition.h:130), so an older decoder is allowed to skip any field it doesn't recognize.
Field 0 — gtid_flags: 00 00
00 → field id = 0
00 → gtid_flags = 0
The transaction contains only row-based events, so FLAG_MAY_HAVE_SBR is clear — same semantics as in Part 5.
Field 1 — SID (UUID): 01 aa ee 25 02 08 04 65 02 22 c5 03 c5 02 e1 02 9c c1 03 11 03 55 02 de ad 03
01 → field id = 1
aa ee 25 02 08 04 65 02 22 c5 03 c5 02 e1 02 9c c1 03 11 03 55 02 de ad 03
→ 16 unsigned chars varint-encoded → 55 77 89 04 02 99 11 f1 b1 b8 4e f0 c4 95 6f eb
Reading each varint individually:
| Wire bytes | Decoded byte | Why |
|---|---|---|
| aa | 0x55 | 0xaa >> 1 = 0x55 |
| ee | 0x77 | 0xee >> 1 = 0x77 |
| 25 02 | 0x89 | trailing-1s=1 ⇒ 2 bytes ⇒ (0x25>>2) | (0x02<<6) = 0x89 |
| 08 | 0x04 | 0x08 >> 1 |
| 04 | 0x02 | 0x04 >> 1 |
| 65 02 | 0x99 | 2 bytes |
| 22 | 0x11 | 1 byte |
| c5 03 | 0xf1 | 2 bytes |
| c5 02 | 0xb1 | 2 bytes |
| e1 02 | 0xb8 | 2 bytes |
| 9c | 0x4e | 1 byte |
| c1 03 | 0xf0 | 2 bytes |
| 11 03 | 0xc4 | 2 bytes |
| 55 02 | 0x95 | 2 bytes |
| de | 0x6f | 1 byte |
| ad 03 | 0xeb | 2 bytes |
Reassembled, the SID is 55778904-0299-11f1-b1b8-4ef0c4956feb. Notice that nine of the sixteen UUID bytes had their high bit set and so cost two varint bytes each — a clean 16-byte UUID would have fit in 16 bytes if the framework had written it as a fixed-size blob, but it didn't.
Field 2 — GNO: 04 0c
04 → field id = 2
0c → signed varint = 3
Decoding the signed varint: unsigned value 0x0c >> 1 = 6; sign bit (low bit of 6) is 0, so the value is 6 >> 1 = 3. GNO = 3 — exactly what SET GTID_NEXT = '…:mytag:3' requested.
Field 3 — Tag: 06 0a 6d 79 74 61 67
06 → field id = 3
0a → varint length = 5
6d 79 74 61 67 → "mytag"
The tag is encoded as a length-prefixed string. The mysql::gtid::Tag class lower-cases the input and rejects anything outside [a-z_][a-z0-9_]{0,31} (tag.h), so on disk we only ever see well-formed ASCII tags.
An empty tag (length = 0) means the source produced a tagged event for a transaction whose GTID actually has no tag. MySQL 8.4+ will still emit a GTID_TAGGED_LOG_EVENT in that case if the binlog has seen any tagged GTID before; the encoding is identical except this field is just 06 00.
Fields 4 & 5 — Parallel-replication timestamps: 08 00 0a 04
08 → field id = 4
00 → last_committed = 0 (signed varint)
0a → field id = 5
04 → sequence_number = 1 (signed varint)
Same semantics as Part 5: last_committed is the sequence number of the commit parent this transaction depends on, and sequence_number is its own logical clock value. Both use zigzag-signed varints because the C++ fields are int64_t.
Field 6 — Immediate commit timestamp: 0c 7f 1c f3 b8 14 24 4a 06
0c → field id = 6
7f 1c f3 b8 14 24 4a 06 → varint = 1770368687207196 µs
This is the longest varint in the event. 0x7f = 0b01111111 has 7 trailing 1-bits, so the framework reads 8 bytes total: the first byte contributes its high bit (a 0 — so the topmost data bit is 0), and the next 7 bytes hold the rest as little-endian.
tail bytes (LE): 1c f3 b8 14 24 4a 06 → 0x064a2414b8f31c
shift left by : 8 - 8 + ((8+7)>>4) = 0
final value : 0x064a2414b8f31c = 1770368687207196 µs
= 2026-02-06 06:04:47.207196 UTC
Compare to Part 5: the same logical field was 7 bytes of fixed int7store there, with bit 55 doubling as a flag for "an original timestamp follows." Here the flag is gone — the next byte will tell us whether field 7 (original_commit_timestamp) is present by its field ID alone.
Field 7 — Original commit timestamp: absent
The next byte is 0x10 → varint = 8. We expected field ID 7, but got 8 — meaning original_commit_timestamp was skipped on encode. The decoder's Field_missing_functor for this field is:
[this]() { this->original_commit_timestamp = this->immediate_commit_timestamp; }
i.e. when the field is missing, assume the original equals the immediate. That's the wire-format way to express "this transaction was committed locally" — and matches original_committed_timestamp=1770368687207196 immediate_commit_timestamp=1770368687207196 from mysqlbinlog.
Field 8 — Transaction length: 10 a1 04
10 → field id = 8
a1 04 → varint = 296
Decoding 0xa1 = 0b10100001: trailing-1s = 1, so 2 bytes. (0xa1 >> 2) | (0x04 << 6) = 0x28 | 0x100 = 0x128 = 296. The whole transaction — this GTID event plus the BEGIN, TABLE_MAP, WRITE_ROWS, and XID that follow — is 296 bytes. We can verify: from position 245 forward, the next-non-GTID event boundaries are 328 → 405 → 461 → 510 → 541, and 541 − 245 = 296. ✓
Field 9 — Immediate server version: 12 43 0f 0b
12 → field id = 9
43 0f 0b → varint = 90600
Decoding 0x43 = 0b01000011: trailing-1s = 2, so 3 bytes. (0x43 >> 3) | ((0x0f | (0x0b << 8)) << 5) = 8 | (0x0b0f << 5) = 8 | 0x161e0 = 0x161e8 = 90600. That decodes back to MySQL 9.6.0 under the usual major*10000 + minor*100 + patch packing.
Fields 10 & 11 — absent
The cursor is now at offset 60 — the end of the payload. No more field IDs follow, so original_server_version and commit_group_ticket are missing and their Field_missing_functors fill in defaults: original equals immediate (90600), and commit_group_ticket = kGroupTicketUnset = 0.
The trailing 4 bytes 78 72 ad 08 are the CRC32, just like every other event in the file.
Visual Breakdown
Position 245: GTID_TAGGED_LOG_EVENT (83 bytes)
┌─────────────────────────────────────────────────────────────────────────┐
│ COMMON HEADER (19 bytes) │
├─────────────────────────────────────────────────────────────────────────┤
│ afae8569 │ 2a │ 01000000 │ 53000000 │ 48010000 │ 0000 │
│ Timestamp │ Type │ ServerID │ Size │ NextPos │ Flags │
│ 1770368687 │ 42 │ 1 │ 83 │ 328 │ 0x0000 │
└─────────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────┐
│ SERIALIZATION FRAMEWORK HEADER (3 bytes) │
├──────────────────────────────┬──────────────────────────────────────────┤
│ 02 │ format version = 1 │
│ 78 │ encoded payload size = 60 │
│ 00 │ last non-ignorable field id = 0 │
└──────────────────────────────┴──────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────┐
│ TLV FIELDS (57 bytes) │
├──────────────────────────────┬──────────────────────────────────────────┤
│ 00 00 │ #0 gtid_flags = 0 (rbr_only) │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 01 aa ee 25 02 08 04 65 02 │ #1 SID = 55778904-0299-11f1- │
│ 22 c5 03 c5 02 e1 02 9c c1 │ b1b8-4ef0c4956feb │
│ 03 11 03 55 02 de ad 03 │ (16 UUID bytes, 25 bytes on the wire) │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 04 0c │ #2 GNO = 3 (signed) │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 06 0a 6d 79 74 61 67 │ #3 Tag = "mytag" (length=5) │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 08 00 │ #4 last_committed = 0 │
│ 0a 04 │ #5 sequence_number = 1 │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 0c 7f 1c f3 b8 14 24 4a 06 │ #6 immediate_commit_timestamp = │
│ │ 1770368687207196 µs │
├──────────────────────────────┼──────────────────────────────────────────┤
│ (id 7 omitted) │ original_commit_timestamp = immediate │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 10 a1 04 │ #8 transaction_length = 296 │
├──────────────────────────────┼──────────────────────────────────────────┤
│ 12 43 0f 0b │ #9 immediate_server_version = 90600 │
├──────────────────────────────┼──────────────────────────────────────────┤
│ (ids 10, 11 omitted) │ original_server_version = immediate │
│ │ commit_group_ticket = 0 (no BGC) │
└──────────────────────────────┴──────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────┐
│ CHECKSUM (4 bytes) │
├──────────────────────────────┬──────────────────────────────────────────┤
│ 7872ad08 │ CRC32 │
└──────────────────────────────┴──────────────────────────────────────────┘
GTID: 55778904-0299-11f1-b1b8-4ef0c4956feb:mytag:3
Tagged vs. Untagged: A Side-by-Side
For the same logical transaction (single INSERT, locally committed, MySQL 9.6.0), the two encodings compare as follows:
| GTID_LOG_EVENT (Part 5) | GTID_TAGGED_LOG_EVENT (this post) | |
|---|---|---|
| Event type | 33 (0x21) | 42 (0x2a) |
| Post-header layout | Fixed: 42 bytes | None — payload is fully variable |
| Field ordering | Implicit (positional) | Explicit field IDs (TLV) |
| SID encoding | 16 raw bytes | 16 varints (16–32 bytes) |
| GNO encoding | 8-byte int8store | signed varint (1–10 bytes) |
| Tag | Not representable | varint length + ASCII chars |
| Optional fields | Length-prefix tricks (MSB flags) | Just omit the field ID |
| Forward-compatible? | Only by appending at the end | Yes — unknown ignorable fields are skipped |
The break-even point on size is somewhere around "ten or fewer SID bytes with the high bit set" — small GNOs and a short or absent tag will usually leave the tagged event a few bytes smaller than its untagged equivalent, despite the per-field ID overhead. Our event is 83 bytes (60-byte payload), versus 79 bytes (56-byte payload) for the untagged event from Part 5; the four extra bytes come from the mytag field that simply doesn't exist in the older format.
Try It Yourself
import struct
import uuid
def read_uvarint(data, off):
"""Decode mysql::serialization unsigned varint at off; return (value, new_off)."""
first = data[off]
num_bytes = 1
while (first >> (num_bytes - 1)) & 1:
num_bytes += 1
high = first >> num_bytes
if num_bytes == 1:
return high, off + 1
tail = int.from_bytes(data[off + 1:off + num_bytes], 'little')
shift = 8 - num_bytes + ((num_bytes + 7) >> 4)
return high | (tail << shift), off + num_bytes
def read_svarint(data, off):
"""Decode signed varint via zigzag."""
u, off = read_uvarint(data, off)
sign = -(u & 1) # 0 if positive, -1 if negative
return (u >> 1) ^ sign, off
GTID_TAGGED_LOG_EVENT = 42
with open('binlog_gtid_tag.000001', 'rb') as f:
f.seek(245)
header = f.read(19)
timestamp, event_type, server_id, event_size, next_pos, flags = \
struct.unpack('<IBIIIH', header)
assert event_type == GTID_TAGGED_LOG_EVENT, f"got type {event_type}"
body = f.read(event_size - 19 - 4)
crc = f.read(4)
off = 0
# Framework header: format version, total encoded size, last non-ignorable field
fmt_version, off = read_uvarint(body, off)
encoded_size, off = read_uvarint(body, off)
last_non_ignorable, off = read_uvarint(body, off)
# Required fields in order. Each field is preceded by its varint field id.
fid, off = read_uvarint(body, off); assert fid == 0
gtid_flags, off = read_uvarint(body, off)
# SID is a std::array<unsigned char, 16>: each byte is its own varint.
fid, off = read_uvarint(body, off); assert fid == 1
sid_bytes = bytearray(16)
for i in range(16):
sid_bytes[i], off = read_uvarint(body, off)
sid = uuid.UUID(bytes=bytes(sid_bytes))
fid, off = read_uvarint(body, off); assert fid == 2
gno, off = read_svarint(body, off)
fid, off = read_uvarint(body, off); assert fid == 3
tag_len, off = read_uvarint(body, off)
tag = body[off:off + tag_len].decode('ascii')
off += tag_len
fid, off = read_uvarint(body, off); assert fid == 4
last_committed, off = read_svarint(body, off)
fid, off = read_uvarint(body, off); assert fid == 5
sequence_number, off = read_svarint(body, off)
fid, off = read_uvarint(body, off); assert fid == 6
imm_commit_ts, off = read_uvarint(body, off)
# Optional tail: any subset of field ids 7, 8, 9, 10, 11, in order.
orig_commit_ts = imm_commit_ts # default when id 7 omitted
transaction_length = None
immediate_server_ver = None
original_server_ver = None
commit_group_ticket = 0 # kGroupTicketUnset
while off < len(body):
fid, off = read_uvarint(body, off)
if fid == 7: orig_commit_ts, off = read_uvarint(body, off)
elif fid == 8: transaction_length, off = read_uvarint(body, off)
elif fid == 9: immediate_server_ver, off = read_uvarint(body, off)
elif fid == 10: original_server_ver, off = read_uvarint(body, off)
elif fid == 11: commit_group_ticket, off = read_uvarint(body, off)
else: break # unknown field — a real decoder would skip it
if original_server_ver is None:
original_server_ver = immediate_server_ver
full_gtid = f"{sid}:{tag}:{gno}" if tag else f"{sid}:{gno}"
print(f"GTID_TAGGED_LOG_EVENT at offset 245 ({event_size} bytes)")
print(f" Framework: version={fmt_version}, encoded_size={encoded_size}, "
f"last_non_ignorable={last_non_ignorable}")
print(f" GTID: {full_gtid}")
print(f" gtid_flags: 0x{gtid_flags:02x}"
f"{' (FLAG_MAY_HAVE_SBR)' if gtid_flags & 1 else ' (rbr_only)'}")
print(f" last_committed={last_committed}, sequence_number={sequence_number}")
print(f" immediate_commit_timestamp={imm_commit_ts} µs"
f" ({imm_commit_ts / 1_000_000:.6f} epoch)")
print(f" original_commit_timestamp={orig_commit_ts}")
print(f" transaction_length={transaction_length} bytes")
ver = immediate_server_ver
print(f" immediate_server_version={ver} "
f"({ver // 10000}.{(ver % 10000) // 100}.{ver % 100})")
print(f" CRC32: {crc.hex()}")
Output:
GTID_TAGGED_LOG_EVENT at offset 245 (83 bytes)
Framework: version=1, encoded_size=60, last_non_ignorable=0
GTID: 55778904-0299-11f1-b1b8-4ef0c4956feb:mytag:3
gtid_flags: 0x00 (rbr_only)
last_committed=0, sequence_number=1
immediate_commit_timestamp=1770368687207196 µs (1770368687.207196 epoch)
original_commit_timestamp=1770368687207196
transaction_length=296 bytes
immediate_server_version=90600 (9.6.0)
CRC32: 7872ad08
Cross-check against mysqlbinlog:
$ mysqlbinlog --no-defaults binlog_gtid_tag.000001 | sed -n '/at 245/,/SET @@SESSION.GTID_NEXT/p'
# at 245
#260206 6:04:47 server id 1 end_log_pos 328 CRC32 0x08ad7278 GTID last_committed=0 sequence_number=1 rbr_only=yes original_committed_timestamp=1770368687207196 immediate_commit_timestamp=1770368687207196 transaction_length=296
...
SET @@SESSION.GTID_NEXT= '55778904-0299-11f1-b1b8-4ef0c4956feb:mytag:3'
Note: The binary log file
binlog_gtid_tag.000001(and every other file used in this series) is available at github.com/altmannmarcelo/presentations/tree/main/binlog.
References
- GTID_TAGGED_LOG_EVENT = 42 — event type constant alongside
GTID_LOG_EVENT = 33 - Gtid_event class definition — shared between tagged and untagged forms
- Gtid_event::define_fields() — declarative TLV field layout
- Gtid_event::Gtid_event(const char*, ...) — common ctor; dispatches to the tagged reader at line 519
- Gtid_event::read_gtid_tagged_log_event() — tagged payload deserialization
- Serializer_default::encode_serializable_metadata() — writes the 3-varint framework header (format version, size, last non-ignorable id)
- write_varlen_bytes_unsigned() / read_varlen_bytes_unsigned() — the unary-prefix varint encoding
- serialization_format_version = 1 — the version byte all
mysql::serializationstreams begin with - Tag class — the
[a-z_][a-z0-9_]{0,31}validator - Unknown_field_policy —
ignore(default) vs.error, which determines whether a missing field is fatal for older decoders
Wrapping Up the Series
That closes the loop on the binary log. Across eleven posts — Part 1 through this one — we've manually decoded every byte of two real MySQL binary log files:
binlog.000024(MySQL 8.0.40), covered end to end in Parts 2–10.binlog_gtid_tag.000001(MySQL 9.6.0), the tagged-GTID variant covered here.
Every event we've looked at maps back to a specific class in the mysql-9.6.0 source tree, and now we have decoders we wrote ourselves that agree with mysqlbinlog byte for byte. From here, the most useful next steps are probably:
- Reading the network half of replication — the same events flow over the source-to-replica protocol with a slightly different framing.
- The
mysql::serializationlibrary itself, which is gradually showing up in other corners of the server (it's no longer GTID-specific). - Writing — or contributing to — a CDC tool that consumes binary logs directly, now that you can stare at the bytes and know exactly what they mean.
Thanks for reading along.
This series is based on a presentation given at the MySQL Online Summit. The goal is to help MySQL users understand what goes under the hood of replication by manually decoding binary log files.
Related articles
Continue reading more about mysql.

MySQLMarcelo Altmann
Replication Internals: Decoding the MySQL Binary Log Part 10: ROTATE_EVENT — Closing the File and Pointing at the Next One
In this tenth post of our series, we decode the ROTATE_EVENT — the event that closes a binary log file and tells every reader, replica or local, where to look next. Introduction The ROTATE_EVENT (event type 4, 0x04) is the bookmark MySQL leaves at the end of a binary log file. It carries two pieces of information: * The name of the binary log file to read next. * The starting position within that next file (always 4, the byte right after the 4-byte magic number from Part 2). Together thos
Marcelo Altmann2026-05-06·10 min read

MySQLMarcelo Altmann
Replication Internals: Decoding the MySQL Binary Log Part 9: XID_EVENT — Transaction Commit
In this ninth post of our series, we decode the XID_EVENT — the smallest event in the binary log, and the one that marks every transactional commit. Introduction Every DML transaction we've decoded so far ends the same way: with an XID_EVENT (event type 16, 0x10). At only 31 bytes on the wire, it carries a single piece of information — an 8-byte transaction identifier — but it does some of the heaviest lifting in MySQL replication. The XID_EVENT is what allows replication to be crash-safe wit
Marcelo Altmann2026-04-29·12 min read

MySQL Vinicius Grippa
Vinicius Grippa
Readyset Is Ready for MySQL 9.7 - Three Commands With rdst
MySQL 9.7.0 LTS landed today, and we had the pleasure of watching the announcement live — and we were the first ones to download. If you've already pulled the binaries and you're poking at it in a lab, here's the news: Readyset already supports it. The point isn't that Readyset happens to work with 9.7. The point is that we were prepared for the launch. Our compatibility matrix has been running 9.7 pre-release builds, so the same readysettech/readyset:latest image you can docker pull right now
Vinicius Grippa2026-04-22·7 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.