← Back to blogPostgreSQL
Optimizing SQL Pagination in Postgres
SQL pagination is a technique to retrieve a subset of records from a Postgres table or result set. It allows you to divide large datasets into smaller, manageable chunks called "pages" and retrieve them one page at a time. Understanding Pagination in Postgres Pagination is commonly used in applications that display data in a paginated format, such as search results, product listings, or user records. It helps improve performance and user experience by loading and displaying only a portion o
Readyset
2024-04-24 · 13 min read
SQL pagination is a technique to retrieve a subset of records from a Postgres table or result set. It allows you to divide large datasets into smaller, manageable chunks called "pages" and retrieve them one page at a time.
Understanding Pagination in Postgres
Pagination is commonly used in applications that display data in a paginated format, such as search results, product listings, or user records. It helps improve performance and user experience by loading and displaying only a portion of the data at a time, reducing the amount of data transferred and processed.
Pagination affects every element of an application's performance, from database queries to network load to user experience. However, poorly optimized pagination can also affect all aspects of an application and can lead to slow response times, increased resource utilization, and poor scalability.
Thus, pagination is a critical performance optimization in Postgres when building high-performance applications because it directly affects their efficiency, scalability, and user experience.
To address these challenges, Postgres offers various pagination techniques and optimizations. Let’s review these pagination techniques to see their advantages and limitations.
Offset and Limit Pagination
The single most important concept to understand when it comes to pagination in Postgres databases is the use of LIMIT and OFFSET clauses.
LIMIT specifies the maximum number of rows to be returned by a query, while OFFSET specifies the number of rows to skip before returning rows from the query result set.
Here's a simple example:
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 0;
This query will return the first ten rows from the users table, ordered by the id column. The OFFSET 0 means it will start from the beginning of the result set.
To get the next page of results, you would modify the OFFSET value:
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 10;
This query will return the next ten rows, starting from the 11th row of the result set.
By adjusting the LIMIT and OFFSET values based on the page number and page size, you can efficiently retrieve paginated results from a large dataset in a Postgres database.
This is a great, simple option for pagination. But you’ll start to see performance degradation with large offsets. As the OFFSET value increases, the database needs to scan and discard a larger number of rows before returning the desired result set. For example, let’s whack up the OFFSET considerably:
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 100000;
Postgres must scan and discard 100,000 rows before returning the desired 10 rows. This can be highly inefficient and slow, mainly if the users table is large. Let’s test this. We’ll spin up a mock table with enough data:
-- Create the 'users' table
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
-- Generate 1,000,000 rows of test data
INSERT INTO users (name, email)
SELECT
'User' || num,
'user' || num || '@example.com'
FROM generate_series(1, 1000000) AS num;
And then paginate through it at different OFFSETs:
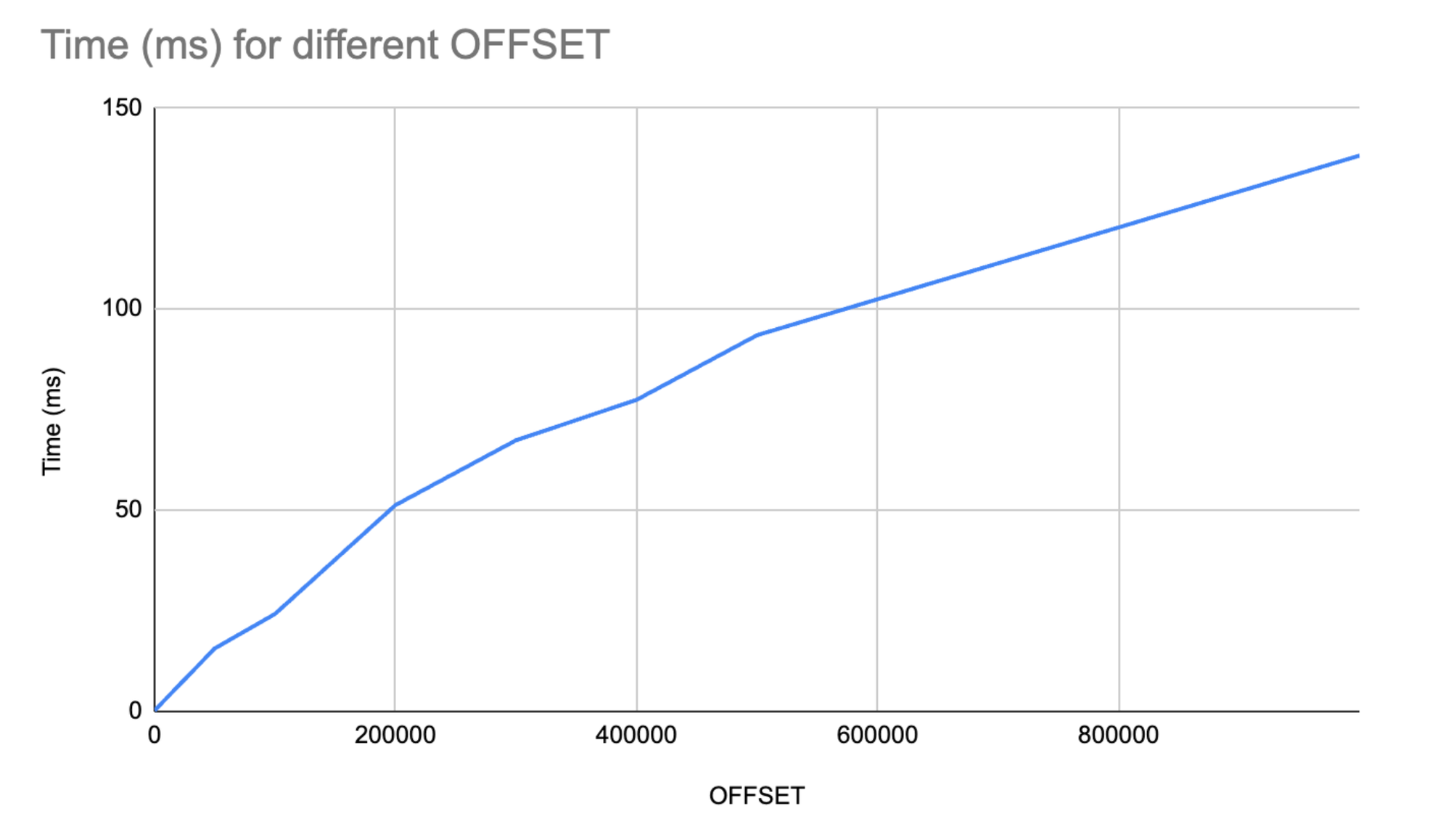
| OFFSET | Time (ms) |
|---|---|
| 0 | 0.283 |
| 50,000 | 15.718 |
| 100,000 | 24.278 |
| 200,000 | 51.329 |
| 300,000 | 67.422 |
| 400,000 | 77.463 |
| 500,000 | 93.524 |
| 999,990 | 138.136 |
As expected, this is roughly a linear (O(n)) time complexity:
Beyond getting consistently slower, or rather, because it gets consistently slower, this pagination technique can lead to consistent results with concurrent updates. The results may be inconsistent or missing if the underlying data is modified (e.g., rows inserted, updated, or deleted) between consecutive paginated queries.
Consider the following scenario:
- Query 1:
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 0; - Query 2:
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 10;
If a new row is inserted or an existing row is deleted between these two queries, the second query may return unexpected results. Rows might be duplicated or skipped entirely.
This approach can also be inefficient with large result sets. When using LIMIT and OFFSET for pagination, the database still needs to generate the entire result set, even if only a small portion is returned to the application. This can be inefficient, especially for queries with complex joins or large result sets. Consider a query like:
SELECT u.*, p.* FROM users u JOIN posts p ON u.id = p.user_id ORDER BY u.id LIMIT 10 OFFSET 10000;
In this case, the database must generate the entire result set, perform the join operation, and discard the first 10,000 rows before returning the desired ten rows. This is resource-intensive and time-consuming.
Cursor-based pagination
Cursor-based pagination relies on using a unique identifier or a timestamp of the last retrieved record as a reference point for fetching the next page of results. Instead of using OFFSET, you keep track of the previous retrieved record and use its identifier or timestamp in the WHERE clause to fetch the next set of records.
-- Fetch the first page
SELECT * FROM users WHERE id > 0 ORDER BY id LIMIT 10;
-- Fetch the next page
SELECT * FROM users WHERE id > <last_id_from_previous_page> ORDER BY id LIMIT 10;
Here, we use the id column as the cursor. You want to choose a unique and stable column that identifies each record in the result set. Common choices include the primary key column or a timestamp column.
We start by fetching the first page with id > 0 and LIMIT 10. For subsequent pages, we use the id of the last retrieved record from the previous page as the starting point and fetch the next set of records. We need to keep track of the cursor value, most likely on the application side, and then use this value to construct the query to fetch the next page.
Cursor-based pagination is more efficient than offset-based pagination because it avoids the need to scan and discard rows. Instead, it directly jumps to the next set of records based on the cursor value. This approach remains efficient even for large offsets because the database can quickly use an index on the cursor column to locate the starting point.
It also produces stable results. Cursor-based pagination provides stable results even if new records are inserted or deleted between page requests. Each page contains the expected set of records based on the cursor value.
Using cursor-based pagination, you should also see reduced database load. By avoiding the need to scan and discard records, cursor-based pagination reduces the database load and resource consumption compared to offset-based pagination.
There are considerations when implementing cursor-based pagination.
- Cursor stability. The cursor column must be unique and immutable. If the cursor value changes between page requests (e.g., due to updates), it can lead to inconsistent results.
- Sorting requirements. Cursor-based pagination relies on a specific sorting order to determine the next set of records. Ensure the query includes an appropriate ORDER BY clause based on the cursor column.
- Application-side tracking. The application needs to keep track of the cursor value for each page and use it to construct the subsequent queries. This adds some complexity to the application code.
- Deleted records. If records are deleted between page requests, cursor-based pagination may result in gaps in the paginated results. The page size may be less than the expected number of records.
Keyset pagination
Keyset pagination takes cursor-based pagination a step further by using a combination of columns to identify each record uniquely. Typically, the columns used for keyset pagination include the primary key and a timestamp or a monotonically increasing value.
-- Fetch the first page
SELECT * FROM users ORDER BY id, created_at LIMIT 10;
-- Fetch the next page
SELECT * FROM users
WHERE (id, created_at) > (<last_id_from_previous_page>, <last_timestamp_from_previous_page>)
ORDER BY id, created_at
LIMIT 10;
Here, we use the combination of id and created_at columns as the keyset. For the first page, we fetch the records ordered by id and created_at and limit the result to 10 rows. For subsequent pages, we use the id and created_at values of the last retrieved record from the previous page as the starting point and fetch the next set of records.
Keyset pagination ensures stable and consistent results even if new records are inserted, or existing records are modified between page requests. It guarantees that each record is uniquely identified and avoids the problem of skipped or duplicated records that can occur with offset-based pagination. However, we can’t jump to a specific page–we only have the option of going to the next page of results.
Optimizing Query Performance for Pagination
Selecting the right type of pagination is only part of the story. Other optimizations are also important to ensure that paginated data is returned efficiently.
The Importance of Indexing
To optimize the performance of pagination queries in Postgres, it's crucial to create appropriate indexes on the columns involved in filtering, sorting, and joining. Indexes help the database quickly locate and retrieve the relevant records without scanning the entire table.
When implementing cursor-based or keyset pagination, create an index on the cursor column or the combination of columns used as the keyset. This allows the database to efficiently find the starting point for each page based on the cursor or keyset values.
For example, let's say we have a users table with an id column as the primary key and a created_at column representing the creation timestamp. To optimize keyset pagination queries, we can create a composite index on (id, created_at):
CREATE INDEX idx_users_id_created_at ON users (id, created_at);
With this index in place, the database can quickly locate the records that match the keyset condition (id, created_at) > (<last_id>, <last_timestamp>) without scanning the entire table.
Similarly, for cursor-based pagination using the id column as the cursor, we can create an index on the id column:
CREATE INDEX idx_users_id ON users (id);
This index enables efficient records retrieval based on the cursor value id > <last_id>.
It's worth noting that while indexes improve query performance, they also introduce overhead for write operations (INSERT, UPDATE, DELETE) and consume additional storage space. Therefore, it's essential to strike a balance and create indexes judiciously based on the specific pagination requirements and the overall workload of the application.
Strategies to Enhance Query Performance
1. Analyze queries with EXPLAIN
Postgres provides the EXPLAIN command, which allows you to analyze the execution plan of a query. By prepending EXPLAIN to your pagination query, you can gain insights into how Postgres executes the query, including using indexes, joins, and sorting operations.
EXPLAIN SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 100000;
The output of EXPLAIN will show you the estimated cost, the number of rows processed, and the operations performed by Postgres. This information helps you identify performance bottlenecks and optimize your queries accordingly.
2. Rewrite complex queries
Sometimes, pagination queries can become complex, especially when involving multiple tables, columns, or complex filtering conditions. In such cases, rewriting the query can improve performance.
For instance, your query may not utilize indexes effectively if it has multiple OR conditions across different columns. For example:
SELECT * FROM users
WHERE (company = 'New York Times' OR city = 'New York')
ORDER BY id LIMIT 10 OFFSET 100000;
If there are indexes on both company and city, Postgres will have to choose between the index and then perform a scan for the other column. Consider rewriting the query using UNION statements instead:
(SELECT * FROM users WHERE company = 'New York Times' ORDER BY id LIMIT 10 OFFSET 100000)
UNION
(SELECT * FROM users WHERE city = 'New York' ORDER BY id LIMIT 10 OFFSET 100000);
This rewritten query allows Postgres to utilize indexes on city and city columns more effectively.
3. Optimize joins
If your pagination query involves joins, ensure the join conditions are optimized. Use appropriate indexes on the join columns to speed up the join operation. Also, consider using query planner hints like JOIN_COLLAPSE_LIMIT to guide Postgres in choosing the most efficient join order.
4. Limit result set size
Pagination is most effective when the result set size is limited. Avoid returning unnecessary columns in your SELECT statement. Only include the columns that are needed to display the paginated results. This reduces the amount of data transferred and processed, improving overall performance.
Efficient pagination is an iterative process that requires continuous tuning and optimization based on your application's specific requirements and data characteristics.
Cache-Aware Pagination
In addition to selecting the appropriate pagination technique and optimizing query performance, leveraging caching strategies can significantly improve the efficiency of paginated queries in Postgres. Caching allows frequently accessed data to be stored in memory, reducing the need to query the database for every request. Let's explore some caching strategies that focus on Postgres capabilities.
Materialized Views
Materialized views are a robust caching mechanism in Postgres. They allow you to store the result of a complex query as a separate table. Materialized views are particularly useful for caching paginated results of queries that involve expensive joins, aggregations, or complex filtering.
To create a materialized view for a paginated query:
CREATE MATERIALIZED VIEW paginated_users AS
SELECT * FROM users ORDER BY id LIMIT 1000;
This materialized view caches the first 1000 rows of the users table, ordered by the id column. Subsequent pagination queries can retrieve data from this materialized view instead of querying the main table.
To refresh the materialized view with the latest data:
REFRESH MATERIALIZED VIEW paginated_users;
Materialized views provide a simple and effective way to cache paginated results, reducing the load on the database and improving query performance. It's important to note that materialized views have some drawbacks. The data in a materialized view becomes stale over time and doesn't automatically reflect the changes made to the underlying tables. To get the latest data, you need to manually refresh the materialized view, which can be time-consuming for large datasets.
Postgres Extensions and Commands for Caching
Postgres offers several extensions that enhance its caching capabilities. Two notable extensions are:
- pg_cron: This extension allows you to schedule and execute periodic jobs within Postgres. You can use it to refresh materialized views or update cached data regularly.
- LISTEN/NOTIFY: These commands allow you to understand when data in your cache changes, thus invalidate and resetting your cache.
You can automate cache management and maintain data consistency in your paginated queries by leveraging these extensions.
Readyset
Readyset is a caching engine that integrates seamlessly with Postgres. It sits between your application and the database as a distributed caching layer. Readyset automatically caches the results of paginated queries and keeps the cached data up to date with the underlying database.
Readyset offers several benefits for cache-aware pagination:
- Automatic caching: Readyset caches the results of paginated queries without requiring changes to your application code.
- Incremental updates: Readyset efficiently updates the cached data as the underlying database changes, ensuring data consistency.
- Seamless integration: Readyset is wire-compatible with Postgres, so you only need to switch out your connection string to start using Readyset in your application—no code changes required.
By leveraging Readyset with Postgres, you can achieve high-performance cache-aware pagination without extensive manual caching implementation. Let’s look at how we can cache one of our queries above. If it is still slow after rewriting a complex query, we can cache it within Readyset. Let’s choose:
SELECT * FROM users WHERE city = 'New York' LIMIT 10 OFFSET 100000
After connecting Readyset, you can run this query and see if it currently supported using:
SHOW PROXIED QUERIES;
Some pagination queries are not currently supported, such as broad SELECT * FROM users queries. If the query is supported, you will see something like this:

If the query is supported you can cache the query using:
CREATE CACHE ALWAYS FROM SELECT email FROM users WHERE city = 'New York' LIMIT 10 OFFSET 100000
With that, the query will be cached. We can check with:
SHOW CACHES;
Which outputs another table:

This shows you that your query is cached and in use. Readyset will automatically update the data in the cache as the underlying table data is updated.
Understanding and optimizing pagination in Postgres is essential for building performant, scalable, and user-friendly applications. It allows developers to make informed decisions about data retrieval, minimize resource utilization, and ensure a smooth user experience when dealing with large datasets. By applying appropriate pagination techniques and optimizations, applications can handle growing data volumes effectively and maintain optimal performance.
But, whether you are using pagination or not, Readyset's wire-compatible caching makes it easy to use low-latency queries and significantly boost the performance of your Postgres database without requiring changes to your application code. Sign up for Readyset Cloud for immediate access to SQL caching, or download Readyset to use on your own infrastructure.
Related articles
Continue reading more about postgresql.

PostgreSQL Rishi Raj Jain
Rishi Raj Jain
Getting started with Django, PostgreSQL, and Readyset
Real-world applications face performance challenges with growing data and user traffic. Caching mitigates these challenges by storing frequently accessed data, reducing database fetches, improving response times, and enhancing application scalability, reliability, and user experience. Readyset is a caching engine for Postgres and MySQL databases, requiring minimal adjustments to existing setups. Its wire-compatible design means that the only modification necessary is to adjust the connection st
Rishi Raj Jain2024-05-16·11 min read
PostgreSQL Marcelo Altmann
Marcelo Altmann
Mastering Query Rewriting for Faster PostgreSQL Performance
When you first spin up your app, the emphasis is on getting started and getting data to your clients. But when you don’t have throughput, you are also not going to have enough concurrency to unveil bad queries. But then you have success. And success means data. More users, more interactions, more everything. Suddenly, queries that performed fine are struggling under the load, hurting performance and scalability. This is all going to mean a far worse user experience when much higher costs becaus
Marcelo Altmann2024-04-11·9 min read
PostgreSQLMarcelo Altmann
How Platform Engineers Can Automate Postgres Maintenance
Database maintenance is a crucial ingredient for sustained performance and data integrity. For platform engineers, automating routine tasks within a PostgreSQL environment ensures both reliability and relieves team members from repetitive manual work. Here's a quick rundown of effective approaches: Fine-Tuning Autovacuum PostgreSQL's built-in autovacuum daemon automates essential VACUUM and ANALYZE operations. To get the most out of it: Verifying Autovacuum Enablement Ensure autovacuum
Marcelo Altmann2024-03-27·3 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.