← Back to blogNews
Introducing Readyset: High-Performance SQL Caching Engine
Today, we’re excited to launch Readyset. Our mission is to help developers build faster applications without writing extra code. To accomplish this, we're building a high-performance SQL caching engine and performance monitoring solution that pairs with your existing database to help ensure that query response latencies are always sub-millisecond. Readyset makes it easy for developers to retrofit scalability and performance onto existing applications without code changes. It also enables devel
Readyset
2022-04-13 · 4 min read
Today, we’re excited to launch Readyset. Our mission is to help developers build faster applications without writing extra code.
To accomplish this, we're building a high-performance SQL caching engine and performance monitoring solution that pairs with your existing database to help ensure that query response latencies are always sub-millisecond. Readyset makes it easy for developers to retrofit scalability and performance onto existing applications without code changes. It also enables developers to build new applications from the ground up without having to worry about performance from day zero.
Enhancing SQL Query Performance with Readyset
“The data access layer of a million-dollar idea starts out as a single-server relational database. You’re hardly worried about scale issues – you have an application to write! However, if your million-dollar idea ends up being worth even $100K, you’ll likely find your database struggling to keep up with the scale.” — Vova Galenchenko
Performance has arguably never been more important. Today we're dealing with larger and larger datasets, more complex queries, and fundamentally higher request volumes. The Internet is a much bigger place than it used to be. In a sea of competing apps, being snappy and performant isn't an advantage anymore; it's table stakes. Laggy page load times have been shown to tank key business metrics like conversion rates, so our web apps need to be fast at any scale.
But how do you actually make a fast web app? There's an entire world of performance optimization on the frontend, from bundlers to lazy loading and even offloading complex interactivity to WebAssembly. But the biggest bottleneck in your app’s performance is probably the same as everyone else’s: it’s your database. Your app is only as fast as your slowest query, and as you scale up things inevitably get harder.
Current Standards for Scaling out Databases
Outside of adding indexes for improving performance on specific queries, when confronted with database read performance regressions, there are a few common approaches:
- Build custom caching layers on top of key-value stores like Memcached or Redis. This approach requires developers to write code to maintain the cache, ensuring that results are fresh, and also to rewrite the application to communicate with the new caching layer. Since homegrown caching layers tend not to be SQL-native, the application-cache communication code cannot rely on SQL-compatible tooling like ORMs.
- Provision database read replicas and load balance between them. These read replicas are expensive, prone to replication lag, and since they still compute query results from scratch, often fail to meet latency requirements for the application.
Many workloads require both caches and read replicas, and the resulting tightly-coupled, Frankenstein data layers take significant engineering effort to build and maintain. Moreover, they introduce application and operational complexity that make them prone to failures and outages.
Introducing Readyset
Automating Cache Maintenance Without Code or Database Changes
There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
After speaking to countless developers about their pain points around database read scaling, my Ph.D. labmate Jon Gjengset and I decided to start Readyset to tackle this problem head-on. Readyset expands upon and commercializes the ideas introduced by the popular open-source research project database Noria, which was built over our time at MIT.
At Readyset, we believe there is a better way. Today, we’re excited to introduce our namesake SQL caching engine that fully automates cache maintenance and can be used without code or database changes.
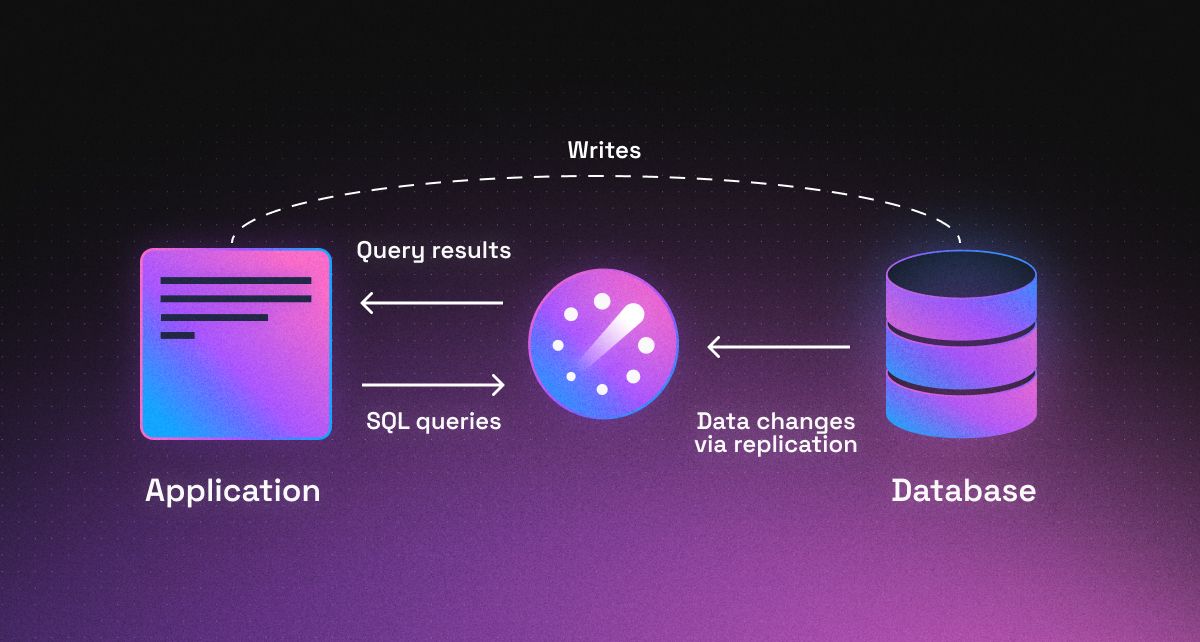
Sounds too good to be true? Here’s a little more about how this actually works:
Readyset supports sub-ms query latencies at scale. Under the hood, Readyset incrementally maintains SQL query result sets over time as the underlying data in your database changes due to writes. Rather than writing code to trigger a cache eviction once some staleness criteria are met, Readyset automatically repairs existing cached results to reflect data changes due to writes. For example, if you’re caching a COUNT, and there’s an additional row that gets written that adds to that count, rather than recomputing the result from scratch, Readyset updates the prior COUNT result by incrementing it by 1. You can read more about Readyset’s internals (sneak peek: partially-stateful, streaming dataflow) here.
Readyset horizontally scales read throughput for cached queries. Readyset cache nodes can be sharded, replicated, and geo-distributed around the world. There is no inter-worker communication between these cache nodes on reads, so throughput scales linearly with the number of cores.
Readyset provides developers with the straightforward experience of a single-node relational database. Readyset is wire-compatible with MySQL and Postgres and can be integrated into existing applications by simply changing a connection string.
What’s Next for Readyset
Readyset’s mission is to help developers build faster applications with little or no effort required. Our first product helps speed up existing databases with a basic caching layer built on incrementally updating views of result sets, but there’s a lot more we’re excited about. Imagine a SQL-oriented CDN that intelligently caches query results around the world based on user access patterns, and automates compliance to data locality regulations introduced by legislation like GDPR with the goal of enabling companies to serve global user bases without re-engineering their data layer. We’re excited for a faster future.
Fueled by $28M from top VCs (read more about our funding here), we’ve grown the team to 19 people strong over the past year, and have partnered with a few early design partners to build out a strong product foundation. We’re actively hiring across tons of roles – check out our careers page for more information!
In the meantime, you can learn more about Readyset by watching our demo and reading our docs. Start caching queries today with Readyset Cloud, or self-host our open-source product, Readyset Core.
If you have questions or comments, feel free to reach out at
info@readyset.io.
Related articles
Continue reading more about news.

News Gautam Gopinadhan
Gautam Gopinadhan
Nobody wants a cache
Every cache on your laptop is invisible: it decides for itself, keeps deciding as the workload moves, and never changes the answer. Database caching is the last place we still do it by hand. Today we're launching the Readyset Platform to close that gap.
Gautam Gopinadhan2026-07-21·10 min read

News Marcelo Altmann
Marcelo Altmann
Your AI now speaks Readyset: announcing the MCP server
Hot on the heels of rdst, the client side performance toolkit, today we're shipping something our customer have been requesting for a long time: native MCP (Model Context Protocol) support in Readyset. Claude, Cursor, Windsurf, and every other MCP-aware agent can now talk to your Readyset directly — inspecting proxied queries, analyzing what's cacheable, and creating or dropping caches in real time. The "copy SQL into a chat window, paste the result back" loop is over. Even better: we're not sh
Marcelo Altmann2026-06-11·5 min read

NewsReadyset
Readyset Launches QueryPilot Guard, a Control Plane for AI-Generated Database Queries
New infrastructure layer brings governance, safety, and cost control to a workload that was never designed to be machine-generated.
2026-06-10·2 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.