
← Back to blogEngineering
How Readyset Handles Window Functions Under the Hood
How Readyset Supports and Optimizes Window Functions Window Functions are an integral part of SQL performance and query optimization, and they're widely supported in production databases today. To achieve our goal of helping our users scale their MySQL and PostgreSQL databases with no code changes, we now support SQL Window Functions as a native part of Readyset. Although we now support standard SQL Window Functions with no code changes, in this blog, we will discuss some of the performance o
Mohamed Abdeen
2025-10-16 · 5 min read
How Readyset Supports and Optimizes Window Functions
Window Functions are an integral part of SQL performance and query optimization, and they're widely supported in production databases today.
To achieve our goal of helping our users scale their MySQL and PostgreSQL databases with no code changes, we now support SQL Window Functions as a native part of Readyset.
Although we now support standard SQL Window Functions with no code changes, in this blog, we will discuss some of the performance optimizations we made and how you can slightly modify your queries to take advantage of them when using Readyset.
Naive Implementation of SQL Window Functions
Readyset keeps an incrementally maintained SQL query cache of your queries by building a streaming Dataflow Graph for each query, where the root nodes of the graph are usually replicas of your tables, and the leaves contain the final result of the cache. Each operation is represented by an inner node like join, union, filter, and a few more.
As inserts (we call them positives), deletes (negatives) and updates (a negative followed by a positive) reach the replicas at the root of the graph, each node processes the change and propagates results to its children, finally the result reaches the leaf where it’s ready to be served, so you don’t have to worry about maintaining your own SQL caches or query results. To learn more about how Readyset works under the hood, refer to the Readyset overview and streaming dataflow pages in our documentation, and this post on how Readyset optimizes queries which summarizes the core ideas behind Readyset.
To support SQL Window Functions, we introduce a new Dataflow Node called Window, which stores a mapping of the view keys (the predicates of the query) that define the window to the rows of the window. When a record reaches the Window node, it does the following:
- Find the window that this record belongs to.
- Apply the change to the window (insert/delete the row).
- Recompute the output of the Function (
SUM,AVG,RANK, etc.) over the window. - Re-emit the window:
- Invalidate the old window (send negatives to child nodes).
- Emit the new window (send positives to child nodes).
This implementation is correct but is it efficient? Imagine if the window had 8 million rows, this means that on every new change, we re-emit 8 million rows (8 million negatives and 8 million positives), which is obviously inefficient. To understand how to optimize, let's review the behaviors of SQL Window Functions.
SQL Window Functions
The syntax we currently support for SQL window functions is FUNCTION OVER([PARTITION BY expr1, expr2, ..] [ORDER BY expr1, expr2, ..]).
This means that the possible combinations of a SQL Window Function OVER clause are:
1. FUNCTION OVER()
2. FUNCTION OVER(PARTITION BY ..)
3. FUNCTION OVER(ORDER BY ..)
4. FUNCTION OVER(PARTITION BY .. ORDER BY ..)
The first two are very similar in their behavior. The main difference is that one doesn't have partitions defined (i.e., treats the entire window as a single partition), and the other defines partitions inside the window. The main similarity is that since the ORDER BY is missing, the output of the SQL Window Function is the same across all rows in each partition (or the entire window, in case of no partitions).
The last two are also similar, since we have an ORDER BY defined, the Window Function runs cumulatively, assigning potentially different values to each row in each partition.
One more thing to note here is that, in the same way a window is defined by the view keys of the query, the partition inside a window is defined by the view keys of the query + the partition key. This idea means that instead of processing windows, we can focus on processing just the partitions.
Note: We currently only support point lookups with SQL Window Functions, range predicates are not supported yet.
Optimization 1: Cumulative vs Non-Cumulative Execution for SQL Window Functions
Imagine you cache this SQL query:
CREATE CACHE FROM
SELECT SUM(amount) OVER (PARTITION BY customer_id ORDER BY timestamp ASC)
FROM transactions;
Now imagine a customer just made a transaction, because of the defined ordering this is a running sum, and the new record will be placed at the bottom of the partition. Do we need to recompute the entire window? Or even the entire partition? No. We can output a positive for that one new transaction with the value from the previous row + the value of the current row as the result of the Function, and that's it!
However, if the SQL Window Function doesn't have an ordering defined, or has an ordering defined but the change affects the top of the partition, we need to recompute the output for the entire partition and send changes twice the size (once in negatives and then again in positives) of the partition through the graph. The more changes propagated through the Dataflow Graph, the more time it takes to keep the query cache up-to-date.
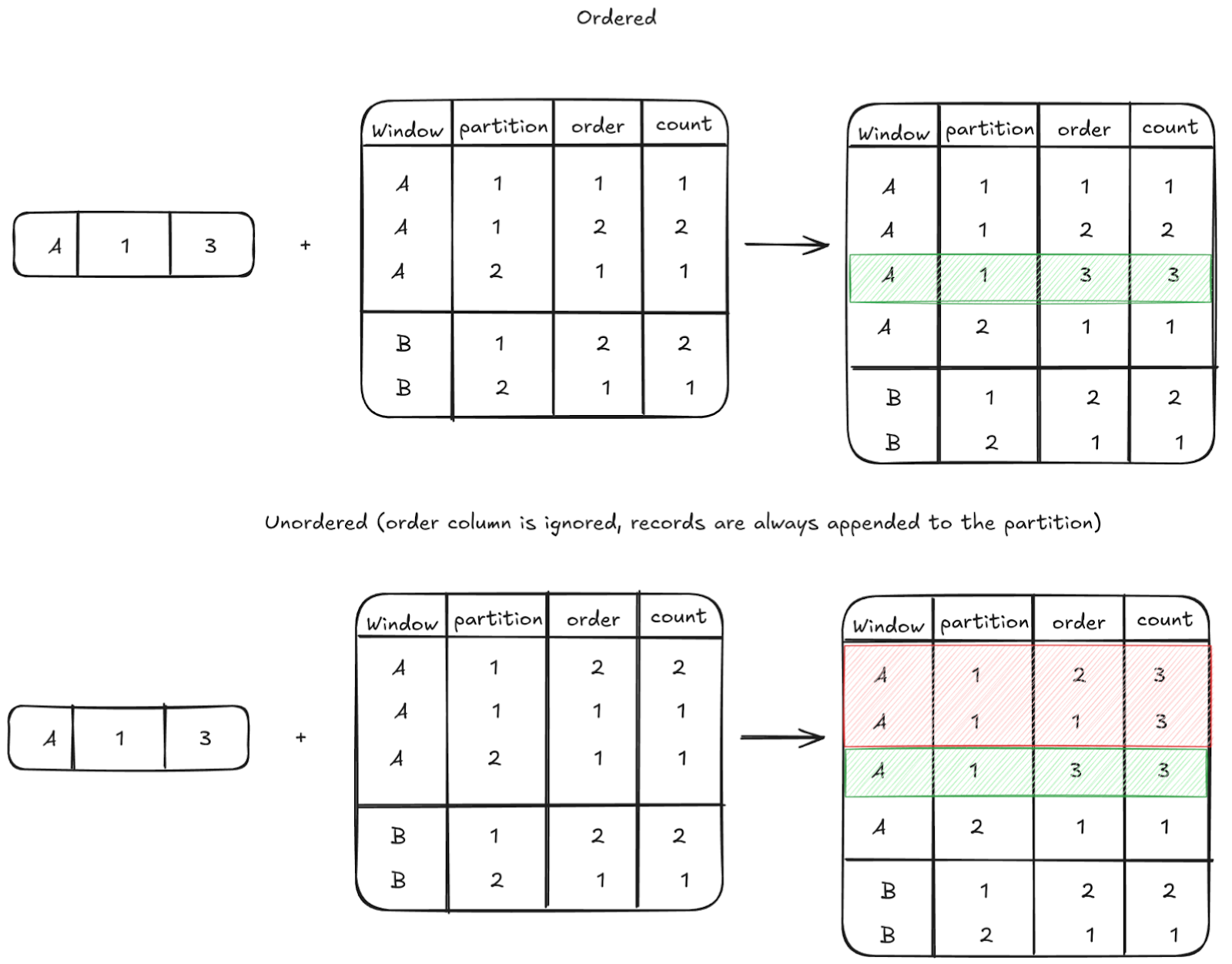
Red rows are re-emitted (invalidated and emitted again), green rows are emitted once.
Optimization: Try to specify an
ORDER BYfor the SQL Window Functions in your queries so that incoming changes are always closer to the bottom of the window. This change helps in reducing the amount of records flowing through the dataflow, and reduces the time required to apply the new change.
To achieve this optimization, each Window Function internally defines two execution subroutines: apply and apply_cumulative. The latter operates on ordered partitions and returns an offset that the node uses to determine how many records to re-emit. In case the offset points to the last row of the partition, we will only emit a single positive/negative record and re-emit zero records; if the offset is 0, that means that we need to re-emit the entire partition.
Optimization 2: Process partitions instead of windows
Imagine you cached this SQL query:
CREATE CACHE FROM
SELECT customer_id,
region,
COUNT(*) OVER (PARTITION BY region, customer_id)
FROM orders
WHERE year = ?;
In this example, the SQL window is defined by the year, and inside the window, we have partitions defined by region and customer_id.
Imagine a customer in a particular region just made a transaction. Do we need to fetch the entire window, filter the relevant region and customer_id, apply the change, and then re-emit the window? No. We only need to diff that specific partition, since changes to that partition don't affect the rest of the window.
While we still need to scan through the window to find the affected partition, this optimization reduces the number of diffs sent through the graph and reduces the time required to apply the changes.
Optimization: If you can't specify an
ORDER BYto take advantage of the first optimization, try to choose your view keys and partition keys so the sizes of the partitions are minimized.
By treating cumulative updates differently and tracking partitions instead of windows, Readyset makes SQL window functions efficient in a streaming dataflow environment. These optimizations let you use familiar SQL constructs while keeping write latency low; all while staying true to our goal of requiring minimal code changes.
Related articles
Continue reading more about engineering.

Engineering Michael Victor Zink
Michael Victor Zink
From parser combinators to hand-written TDOP: On adopting sqlparser-rs at Readyset
How Readyset replaced its homegrown SQL parser with sqlparser-rs, improving performance, reducing maintenance overhead, and tackling a years long backlog of parsing edge cases along the way.
2026-05-21·19 min read

Engineering Vassili Zarouba
Vassili Zarouba
How Readyset Rewrites Your SQL: Inside the Query Transformation Pipeline
Why Query Rewriting Matters for Dataflow Most databases work the same way: a query arrives, the engine builds an execution plan, scans tables, joins rows, filters, aggregates, and returns the result. Every time the query runs, the work repeats from scratch. This pull-based model has served relational databases for decades, but it carries an inherent cost: read latency is proportional to the complexity of the query and the size of the data it touches. Readyset takes a fundamentally different ap
Vassili Zarouba2026-04-28·17 min read

EngineeringMichael Victor Zink
/brutal-review and the new 80/20 rule
(Mistakes and em-dashes are my own.) We have a Claude Code command in our monorepo which is a good example of what I’m calling the "80/20 token rule": if it takes 20M LLM tokens to write a feature, you should spend 80M on ensuring quality: safety measures, testing, and of course code review. If software quality was an open problem before, then agentic engineering has blown it even more wide opener. At a high level, here's what it does: 1. Read the patch to review and all related code. 2. Ha
2026-02-03·22 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.