← Back to blogDatabase Scaling
Horizontal scaling with Postgres replication
Modern applications demand scalability to support growing user bases, real-time responsiveness, and large data volumes. But as applications grow, vertical scaling by adding more compute resources has an upper limit. Once those limits are hit, you’ll need to figure out horizontal scaling by adding more servers into your environment. As most applications are typically read-heavy, the first step to scaling out your database is by adding read replicas to handle the additional load placed on them.
Brian Morrison II
2025-01-27 · 8 min read
Modern applications demand scalability to support growing user bases, real-time responsiveness, and large data volumes. But as applications grow, vertical scaling by adding more compute resources has an upper limit.
Once those limits are hit, you’ll need to figure out horizontal scaling by adding more servers into your environment. As most applications are typically read-heavy, the first step to scaling out your database is by adding read replicas to handle the additional load placed on them. However, replication can introduce challenges such as replication lag, effective load balance, and ensuring smooth failover.
In this article, we’ll explore how read replicas can be used for scaling, how to set up Postgres replication, and various considerations when configuring replication. We’ll also cover how Readyset can address the complexities of database scaling by allowing you to scale reads without the operational overhead of managing replicas.
PostgreSQL Scaling: Vertical vs horizontal
There are a number of ways to scale a database environment.
The first step is adding resources such as CPU and memory. These additional compute resources help the server process queries and return responses more quickly. At the start, this approach works well, but the cost to add resources eventually outweighs the benefits.
This process is known as vertical scaling since all changes occur on a single server.
Horizontal scaling is done by adding additional database servers into the environment and distributing queries across them to spread the load. Scaling out a database environment is typically handled in multiple phases as the application grows, with read replicas being a common approach.
Understanding readreplicas and their purpose
As the name implies, a replica is a copy of the database that resides on another server.
A database environment with replication configured has one primary and one or more replicas. The primary is the only server permitted to manipulate the data and will dispatch its changes to the replicas to keep them updated. Since requests to read data do not change it in any way, these queries may be served by the primary or any replica in the environment.
By default, Postgres only supports environments with one primary and multiple replicas.
While third-party solutions are available to enable writing to multiple servers in the environment, this configuration is generally not recommended as it can cause data conflicts and issues restoring data if needed.
Beyond processing SELECT queries for your applications, read replicas are also well suited for other read-heavy loads such as analytical processing, reporting, or ETL workflows.
Replication types
Streaming replication
Streaming replication (sometimes also called physical replication) involves streaming the changes made to the blocks in the underlying storage to each of the replicas. Streaming replication is conceptually easier to understand as it creates a one-for-one copy of the data. It’s also relatively simple to configure and is a very performant choice if you need an exact copy of your database.
But because there is little control over what’s replicated, it can be rather bandwidth-intensive and is not recommended for replicating across large geographical distances. Streaming replication also requires the underlying storage for each server in the environment to match, even down to the database location on the filesystem.
Logical replication
Logical replication is more flexible than streaming replication by letting you be selective on what data within the database gets replicated. This includes subsets of the data within the database, as well as replicating data from multiple servers into a single replica. As transactions are executed on the primary, those statements are sent to the replicas instead of the storage block changes.
This extra flexibility comes at the cost of being more complex to configure. DDL statements are not replicated either, so any changes to the database schema made on the sources will need to be manually executed on the replicas.
| Attribute | Streaming Replication | Logical Replication |
|---|---|---|
| Replication Method | Binary-level replication of WAL logs | Replication of specific tables/data sets |
| Flexibility | Entire database must be replicated | Selective replication supported |
| Bandwidth Usage | Higher, as full WAL logs are transmitted | Lower, as only specific data changes are replicated |
| Use Cases | Disaster recovery, scaling read replicas | ETL pipelines, multi-tenant apps |
How to set up PostgreSQL replication
Let’s explore the steps involved in configuring replication within a Postgres environment.
This demo will involve two servers, both running Ubuntu 24.04 LTS with a base Postgres 16 installation. Both servers are already configured to allow remote connections.
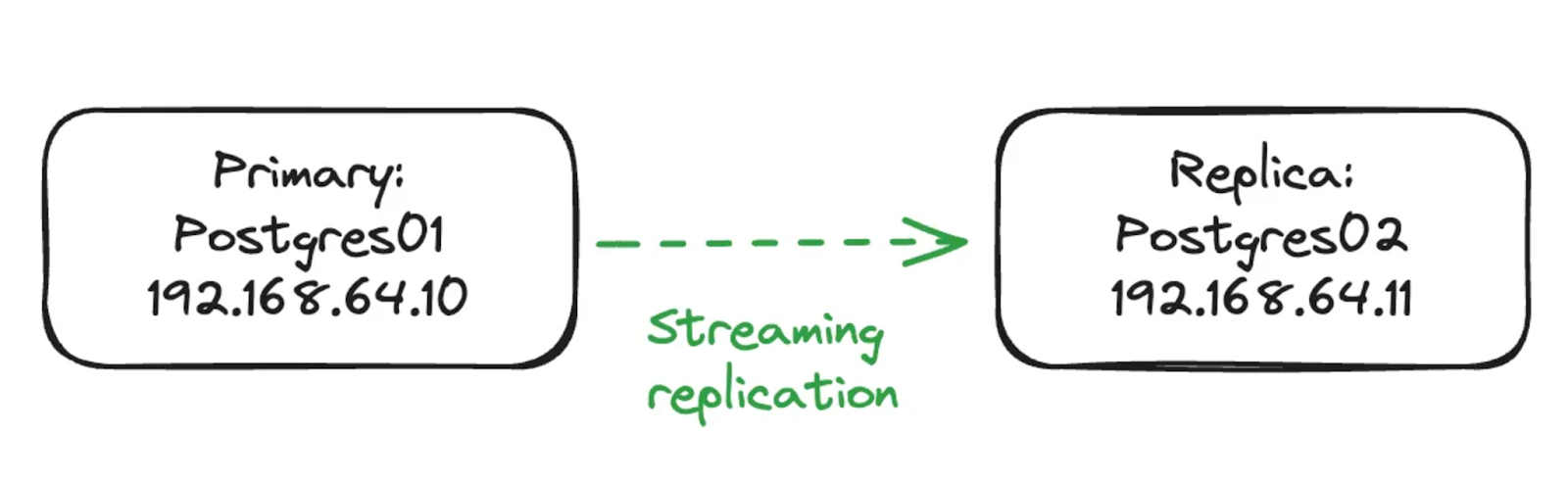
The primary has a single database called tasksdb with the following schema:
create table tasks(
id serial primary key,
name text not null,
created_on timestamp not null default now()
);
That table also has two records in it:
tasksdb=# select * from tasks;
id | name | created_on
----+---------------------+----------------------------
1 | Clean the dishes | 2024-07-02 14:17:54.694071
2 | Organize the office | 2024-07-02 14:17:54.694071
(2 rows)
Configure the primary
The first thing to do is create a new user on the primary server that will be used to replicate data.
create user replication_user
with replication encrypted password 'replication123';
The pg_hba.conf which controls access to the server will need to be edited to permit replication_user to replicate data. The following command will open that file:
sudo nano /etc/postgresql/16/main/pg_hba.conf
Adding the following line to the end will allow replication by replication_user from the host 192.168.64.11, the address of the replica in my environment:
host replication replication_user 192.168.64.11/32 md5
Now restart the Postgres service on the primary:
sudo systemctl restart postgres
Configure the replica
On the replica, start by clearing out the default data directory that is preconfigured when installing Postgres. This command (as well as the next) is run as the postgres user to keep system permission intact:
sudo -u postgres rm -r /var/lib/postgresql/16/main
Next, run pg_basebackup which will take a snapshot of the primary and copy all of the data to the replica:
sudo -u postgres pg_basebackup -h 192.168.64.10 \\
-p 5432 \\
-U replication_user \\
-D /var/lib/postgresql/16/main \\
-Fp -Xs -R
Here is an outline of what each parameter does:
-hdefines the hostname of the primary server.-pis the port that Postgres is using on the primary.-Uis the user that will be used to connect to the primary.-Dspecifies the local directory to which the data will be copied.-Fpprevents the process from creating a .tar file, leaving the file structure as is.-Xswill stream changes from the WAL as they are committed to the primary.-Rboth signals to the replica that the backup is for a replica, as well as configures the primary with the necessary replication info.
Provide the password for replication_user when prompted (it was set to replication123 when created earlier in this guide).
Finally, restart Postgres on the replica.
sudo systemctl restart postgres
Test replication
On the replica, connect to the database using psql like so:
sudo -u postgres psql
Now connect to the tasksdb database and run a select statement:
postgres=# \\c tasksdb
You are now connected to database "tasksdb" as user "postgres".
tasksdb=# select * from tasks;
id | name | created_on
----+---------------------+----------------------------
1 | Clean the dishes | 2024-07-02 14:17:54.694071
2 | Organize the office | 2024-07-02 14:17:54.694071
(2 rows)
Back on the primary, connect to the database and insert a row into the table like so:
tasksdb=# insert into tasks (name) values ('Write the article');
INSERT 0 1
On the replica, run the same select statement as before and notice how the inserted row exists here as well:
tasksdb=# select * from tasks;
id | name | created_on
----+---------------------+----------------------------
1 | Clean the dishes | 2024-07-02 14:17:54.694071
2 | Organize the office | 2024-07-02 14:17:54.694071
3 | Write the article | 2024-07-02 14:37:01.909126
(3 rows)
However, inserting a record will fail as it is a read-only replica:
tasksdb=# insert into tasks (name) values ('This wont work');
ERROR: cannot execute INSERT in a read-only transaction
Challenges of managing read replicas
Replication is a good start to horizontal scaling , but there are some downsides to keep in mind.
Failover
The first is how to shift traffic to a replica in case the primary gets taken offline for any reason. This can include creating scripts that are executed manually to get the desired effect or an external solution like Pgpool-II to detect failures and move traffic automatically. In either case, creating a solid failover playbook and testing it regularly is critical to keeping your data online in case of disaster.
Load balancing requests
Out of the box, Postgres does not have any native load balancing for read requests.
One solution is to use separate connection strings managed directly in the application. This is rather straightforward to implement but means adding more code to manage and maintain. Pgpool-II (along with other third-party solutions) can be used to automatically load balance requests as well as implement connection pooling, but this also requires additional infrastructure to operate properly.
Replication lag
Replication is a network-bound operation, some delay between when the data is written to the primary and when it’s available on a replica.
Asynchronous replication writes data to the primary first and replicates it to replicas afterward. This approach minimizes write latency on the primary but can result in replication lag, leading to eventual consistency issues like stale reads during high traffic.
Synchronous replication, on the other hand, requires the primary to wait for confirmation from replicas before committing data. While this ensures consistency, it introduces higher write latency, which can become a bottleneck in applications that require low-latency writes.
Topology complexities
Adding even a single replica also increases the complexity of your database topology. The more of these considerations you try to address, the more complex the environment gets, of which managing is a skill set in itself. In fact, companies with sufficiently complex database environments often have teams dedicated to keeping things working as expected.
Readyset as your read replica
Replication is often the go-to strategy for scaling read-heavy workloads, but as we just covered, it can introduce significant complexity in configuration,synchronization, and operational overhead. Modern applications require a solution that not only scales effectively, but simplifies infrastructure management. This is where Readyset becomes essential.Readyset is a caching solution that sits in front of your Postgres database and automatically caches queries. Instead of sending read requests to the database server, Readyset responds directly with data in its cache, reducing database load and improving response times by 100x or more. Unlike traditional replication, Readyset integrates seamlessly with Postgres protocols, requiring minimal setup and zero code changes.
If you want to learn more about how Readyset can simplify scaling your Postgres database, you can get started with a free trial here.
Related articles
Continue reading more about database scaling.

Database Scaling Vinicius Grippa
Vinicius Grippa
Caching Supabase with Readyset over IPv6: the AWS and Docker pieces that have to line up
Supabase's direct Postgres endpoint is IPv6-only, and a fresh AWS account has no IPv6 enabled. This walkthrough covers the exact VPC, subnet, and Docker configuration needed to run Readyset in front of Supabase on EC2, with three deployment paths: host network, dual-stack bridge, and Linux package.
2026-08-18·17 min read

Database Scaling Gautam Gopinadhan
Gautam Gopinadhan
The Hidden Complexity of Postgres Scaling Architectures
The OpenAI Postgres scaling article has been making the rounds, and for good reason. The piece does two things extremely well. First, it shows just how Postgres can be pushed far beyond what most teams assume is possible. Second, it makes clear that workloads at this scale don’t run on databases alone; they rely on caching, proxies, and careful query traffic management. It’s a rare public look at what it actually takes to run Postgres at serious scale. Why Scaling PostgreSQL at High Traffic
Gautam Gopinadhan2026-01-27·4 min read

Database Scaling Tanmay Sinha
Tanmay Sinha
Does Your Black Friday Database Scaling Strategy Involve Duct Tape and Prayers?
It Might Be Time to Rethink How You Scale MySQL for Peak Demand As Black Friday and Cyber Monday approach, many engineering teams prepare for their annual database performance stress test. The surging traffic, unpredictable spikes, and sleepless nights spent watching database dashboards. The typical response is familiar: add more replicas, increase compute resources, and pray everything holds. But this approach to database scaling is reactive, costly, and fragile. What begins as a quick fix be
Tanmay Sinha2025-10-21·4 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.