← Back to blogDatabase Scaling
The Hidden Complexity of Postgres Scaling Architectures
The OpenAI Postgres scaling article has been making the rounds, and for good reason. The piece does two things extremely well. First, it shows just how Postgres can be pushed far beyond what most teams assume is possible. Second, it makes clear that workloads at this scale don’t run on databases alone; they rely on caching, proxies, and careful query traffic management. It’s a rare public look at what it actually takes to run Postgres at serious scale. Why Scaling PostgreSQL at High Traffic
Gautam Gopinadhan
2026-01-27 · 4 min read
The OpenAI Postgres scaling article has been making the rounds, and for good reason.
The piece does two things extremely well. First, it shows just how Postgres can be pushed far beyond what most teams assume is possible. Second, it makes clear that workloads at this scale don’t run on databases alone; they rely on caching, proxies, and careful query traffic management.
It’s a rare public look at what it actually takes to run Postgres at serious scale.
Why Scaling PostgreSQL at High Traffic Is Mostly an Architecture Problem
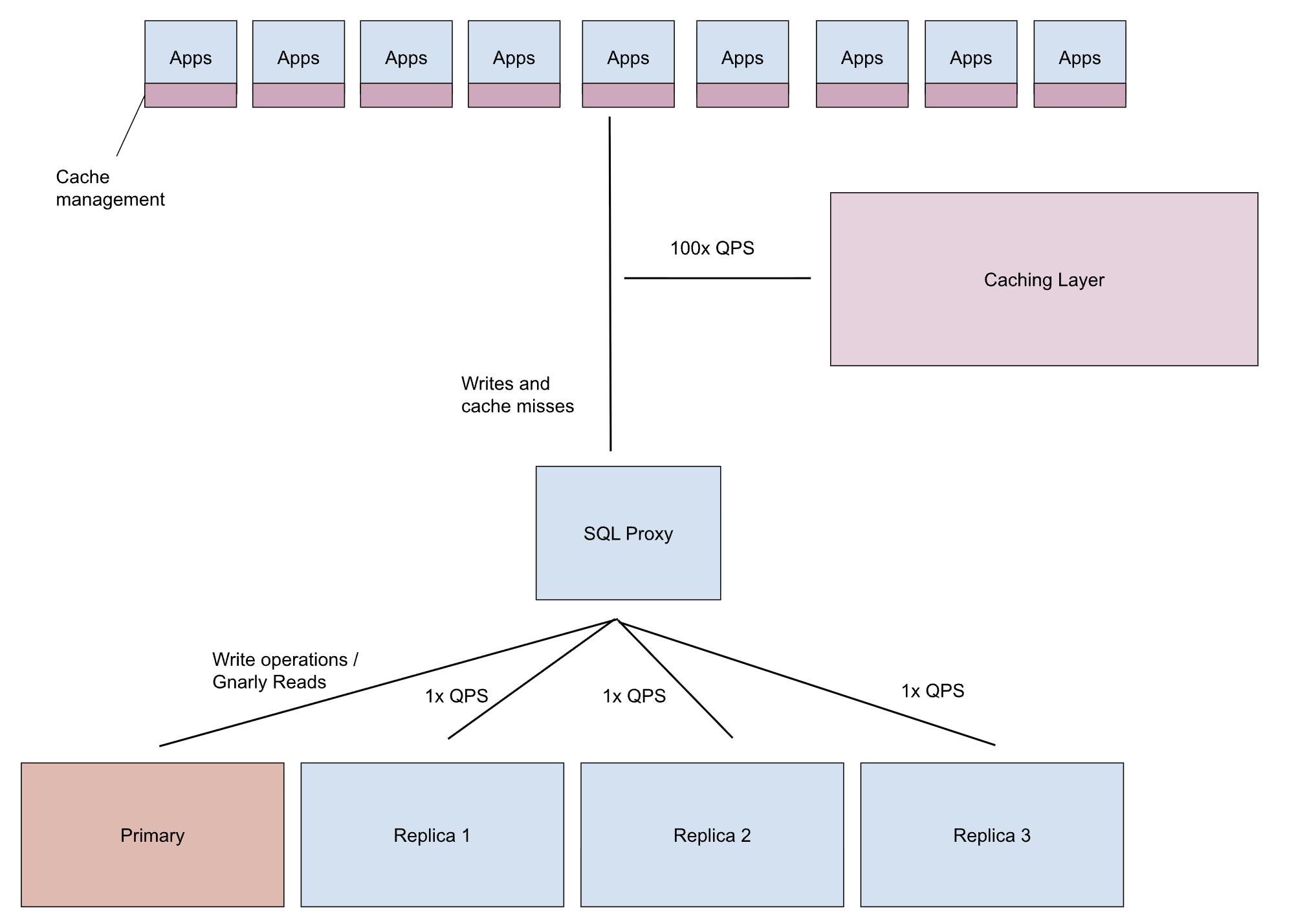
Before getting to the conclusions, it’s worth calling out something the article only hints at but doesn’t fully spell out: the amount of work the infrastructure and developers are doing to make this system viable, and how much of that work effectively turns infrastructure and application development into a big investment.
In the architecture described, applications are explicitly written to read from a caching layer first. Only on cache misses do requests flow through a SQL proxy and land on replicas or the primary. Under steady state, this works well. Under stress, cache invalidations, migrations, overload, and traffic floods the database tier, and the system has to absorb that shock gracefully.
That resilience doesn’t come for free. It requires sustained human effort, deep operational discipline, and teams that are willing to treat infrastructure as a primary product.
Every application team has to understand caching semantics. Redis has quietly become the tax teams accept for not fixing data access at the right layer. They have to decide what to cache, how long to cache it, and how to keep it coherent. Every new feature carries that tax - forever. Over time, developer velocity slows, operational complexity grows, and a large amount of capital is locked into maintaining the caching tier itself.
This isn’t a critique of OpenAI’s choices. If you’ve already committed to this architecture, you’re well aware of the tradeoffs and you’re probably staffed appropriately to manage them.
But it’s not the only way to get there.
Query Isolation as a Scaling Lever
One of the key takeaways people latched onto from the article is that Postgres scales only after you isolate bad queries from good ones. That’s absolutely right. Query execution cost varies wildly, and databases don’t isolate queries by default. One poorly behaved query can degrade everything else.
Traditionally, teams solve this with a combination of read replicas, PgBouncer, and application-level routing. Many of these so‑called best practices were designed for a world where humans wrote the queries and could be reasoned with. It works but it requires constant attention and discipline.
There’s a simpler contract you can offer application teams.
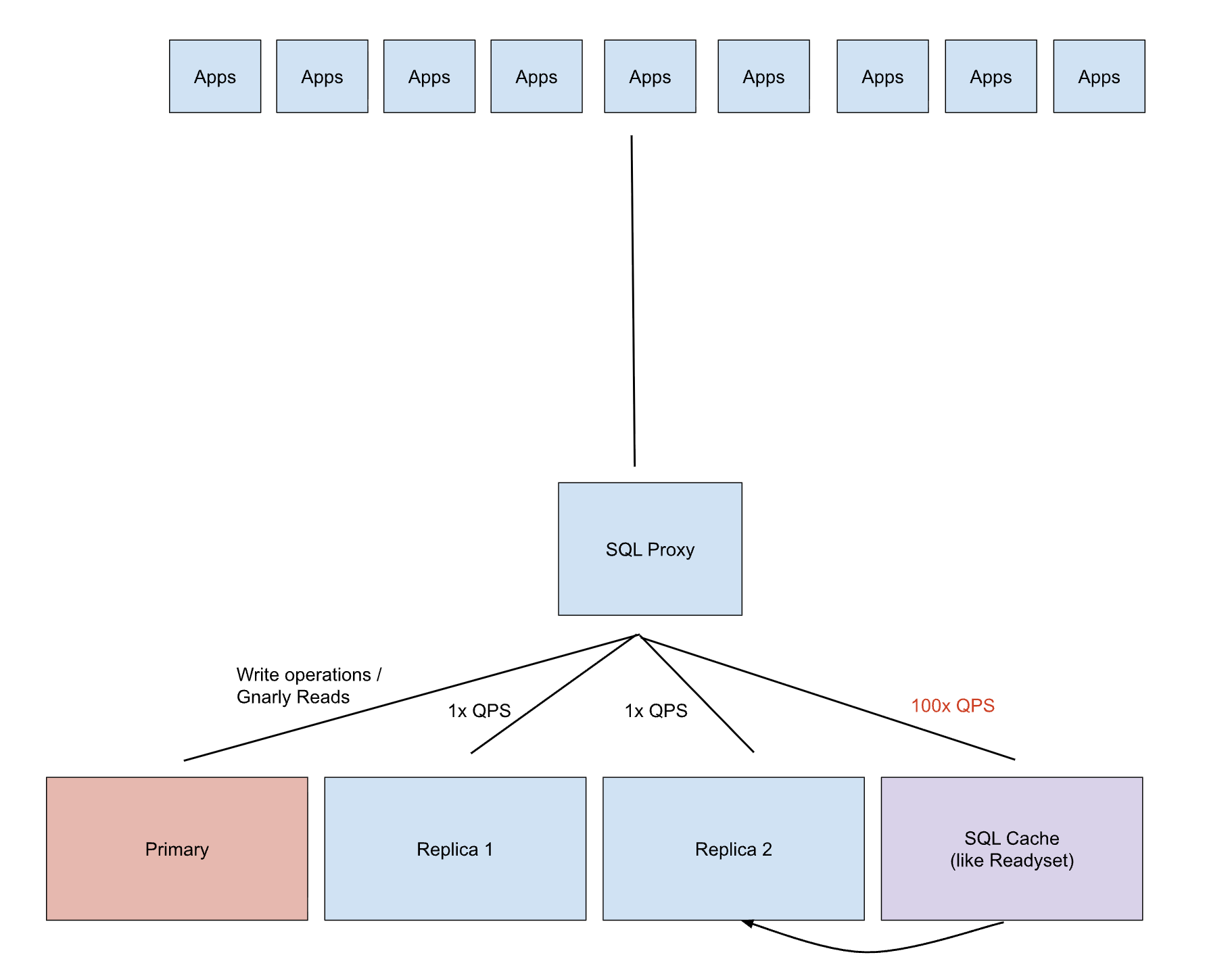
Instead of pushing caching decisions into every app, you can move them into the SQL layer itself.
When queries flow through an intelligent SQL proxy backed by an efficient SQL cache, the system can:
- Route writes to the primary
- Serve non-cacheable gnarly reads from Replicas (or the primary)
- Automatically cache high-impact queries close to the database
From the application’s point of view, nothing changes. Except, no Redis APIs. No bespoke cache invalidation logic. Just SQL.
This architecture is already running in production at multiple companies. It delivers similar scaling characteristics to the more complex Redis-heavy design, but with a far simpler application deployment model.
LLMs Break the Assumptions Behind Application-Level Caching
This matters even more as the shape of applications changes.
Historically, applications were human-coded. Query patterns were relatively stable, and engineers could reason about which queries deserved caching.
That’s no longer true.
LLM-built and agentic applications generate far more unpredictable query workloads. Asking application code to manage cache correctness in these systems isn’t just brittle, it’s a category error. There’s no practical way to predeclare which queries should live in Redis and which shouldn’t. The system needs to observe behavior and adapt automatically.
Caching Belongs in the SQL Layer
This is where SQL-native caching shines.
A well-implemented SQL cache can refresh results automatically, maintain consistency, and adapt as workloads change. Developers don’t need to hand-roll refresh logic for every dataset the way they do with application-level caches.
Add a dynamic SQL proxy that can identify problematic queries and cache them at runtime, and the system adjusts as load shifts, without constant intervention.
Readyset supports both deep caching for ultra-low-latency paths and shallow caching that replaces large classes of Redis usage. QueryPilot handles query selection dynamically. Deep caching relies on the replication stream for low-latency cache maintenance, while shallow caching does not and therefore places less strain on replication throughput.
The result is simple: platform teams regain control, application teams move faster, and the infrastructure becomes easier to reason about.
Choosing Where To Place Database Complexity
The OpenAI article is a great validation of something we’ve believed for a long time:
- Query cost variance matters
- Queries are not isolated by default
- Caching is essential to controlling database performance
- Application-level query caching is increasingly the wrong abstraction
Postgres is an excellent foundation. So is MySQL. Your data should live wherever it makes sense for you. The real difference comes down to where you choose to place caching intelligence in the system.
You can build world-class performance by throwing people and processes at the problem. At some point, scaling Postgres stops being a database problem and starts being a question of where you’re willing to let complexity live.
Or you can let the data plane do more of the work for you.
Related articles
Continue reading more about database scaling.

Database Scaling Vinicius Grippa
Vinicius Grippa
Caching Supabase with Readyset over IPv6: the AWS and Docker pieces that have to line up
Supabase's direct Postgres endpoint is IPv6-only, and a fresh AWS account has no IPv6 enabled. This walkthrough covers the exact VPC, subnet, and Docker configuration needed to run Readyset in front of Supabase on EC2, with three deployment paths: host network, dual-stack bridge, and Linux package.
2026-08-18·17 min read

Database Scaling Tanmay Sinha
Tanmay Sinha
Does Your Black Friday Database Scaling Strategy Involve Duct Tape and Prayers?
It Might Be Time to Rethink How You Scale MySQL for Peak Demand As Black Friday and Cyber Monday approach, many engineering teams prepare for their annual database performance stress test. The surging traffic, unpredictable spikes, and sleepless nights spent watching database dashboards. The typical response is familiar: add more replicas, increase compute resources, and pray everything holds. But this approach to database scaling is reactive, costly, and fragile. What begins as a quick fix be
Tanmay Sinha2025-10-21·4 min read

Database ScalingTanmay Sinha
WordPress with QueryPilot: Instant Database Scaling Without Code Changes
Introduction We at Readyset, recently launched the public beta of QueryPilot, an automatic query caching layer designed to make scaling relational databases effortless. QueryPilot analyzes real-time query traffic, identifies high-impact patterns, and transparently caches results, without requiring code changes or database tuning. In an effort to show how easy it would be for applications to take advantage of QueryPilot, we put it to test against one of the most prolific content platforms on t
Tanmay Sinha2025-08-19·5 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.