← Back to blogQuery Optimization
Demystifying EXPLAIN and EXPLAIN ANALYZE
You've crafted the ideal SQL query. It's beautiful. A work of art. Then, it takes seconds to execute and hangs your entire application. What went wrong? You need a way to look under the hood of SQL and understand the inner workings of your query. “Under the hood” is precisely what the EXPLAIN and EXPLAIN ANALYZE commands were built for–to guide you through the labyrinth of query optimization. These offer a glimpse into the database optimizer, revealing how your query is executed and identifying
Marcelo Altmann
2024-11-13 · 11 min read
You've crafted the ideal SQL query. It's beautiful. A work of art. Then, it takes seconds to execute and hangs your entire application.
What went wrong? You need a way to look under the hood of SQL and understand the inner workings of your query. “Under the hood” is precisely what the EXPLAIN and EXPLAIN ANALYZE commands were built for–to guide you through the labyrinth of query optimization. These offer a glimpse into the database optimizer, revealing how your query is executed and identifying potential performance bottlenecks.
Well, they kind of do that. They output a somewhat confusing waterfall of data on your query that you must learn to understand before optimizing your query. Here, we want to make that output a little clearer and demystify EXPLAIN and EXPLAIN ANALYZE so you can use them better in your query optimization.
What are EXPLAIN and EXPLAIN ANALYZE?
EXPLAIN and EXPLAIN ANALYZE analyze the database optimizer's execution plan for a query, but they provide different levels of detail.
EXPLAIN
When you use EXPLAIN followed by a query, it displays the execution plan the database optimizer chose for that query. The optimizer determines the most efficient query execution based on available indexes, statistics, and query structure.
This execution plan shows the steps and methods the database will use to retrieve the data, such as the order of table scans, joins, and indexes used.
EXPLAIN estimates the “cost” and number of rows returned for each step in the plan. The "cost" is an arbitrary unit the optimizer uses to represent the estimated time and resources required to execute that step.
The important thing about running EXPLAIN on its own is that it does not execute the query; it only analyzes and displays the plan. This is good because it lets you understand a query's performance without modifying data. As it isn’t running the query, EXPLAIN is often faster than EXPLAIN ANALYZE.
But this good also leads to the bad. As EXPLAIN isn’t running the query, the output is effectively the query optimizer’s best guess at what should happen. The output is based on the optimizer's estimates based on statistics and assumptions, which can be outdated or inaccurate, especially for complex queries or large datasets. It may not reflect the actual execution time or the exact number of rows processed.
EXPLAIN ANALYZE
EXPLAIN ANALYZE goes a step further than EXPLAIN. In addition to displaying the execution plan, it executes the query and provides real-time statistics about the query's execution. It shows the actual time taken for each step of the plan, the number of rows returned, and the total execution time.
This means EXPLAIN ANALYZE provides more accurate and detailed information than EXPLAIN because it reflects the actual execution of the query. This execution means you can use EXPLAIN ANALYZE to help identify performance bottlenecks and inefficiencies in the query.
The pros and cons are then the inverse of EXPLAIN. The good part of EXPLAIN ANALYZE is that you get actual data on your query–not the optimizer's best guess. The bad part is that it is slower, and you’ll modify data when you use it with write operations.
EXPLAIN vs EXPLAIN ANALYZE
So, the differences between EXPLAIN and EXPLAIN ANALYZE are:
- Execution: When you use
EXPLAIN, the query is not executed. It only analyzes the query and generates an execution plan based on the optimizer's estimates. The database engine doesn't retrieve or process any data. On the other hand,EXPLAIN ANALYZEexecutes the query and provides the actual execution statistics along with the execution plan. It processes the data and returns the results like running the query normally. - Performance Statistics: The output of
EXPLAINincludes estimated costs and row counts for each step in the execution plan. These estimates are based on the optimizer's statistical information and assumptions. However, they are not actual measurements from running the query. In addition to the execution plan,EXPLAIN ANALYZEprovides actual performance statistics. It shows the actual time taken for each step, the number of rows processed, and the total execution time. These statistics reflect the actual execution of the query. - Accuracy: The cost estimates and row counts in the
EXPLAINoutput are based on the optimizer's statistical information, which may not always be accurate or current. The actual execution of the query might differ from these estimates. SinceEXPLAIN ANALYZEexecutes the query, its performance statistics are accurate and reflect the actual execution behavior. It gives you exact numbers based on the current data and system state. - Impact on Data: Using
EXPLAINdoes not modify any data because the query is not executed. It is a safe operation with no side effects on the database. When you useEXPLAIN ANALYZE, the query is executed, and any modifications (e.g.,INSERT,UPDATE,DELETE) specified in the query will be performed. It can change the data in the database, so it should be used cautiously. - Overhead: Running
EXPLAINhas minimal overhead because it only analyzes the query and generates the execution plan. It doesn't involve actual data retrieval or processing. SinceEXPLAIN ANALYZEexecutes the query, it incurs the same overhead as running the query normally. It can be slower and consume more resources thanEXPLAIN, especially for complex queries or large datasets.
When will you use either? EXPLAIN is useful when you want to understand how the database optimizer plans to execute a query without actually running it. It helps analyze the query structure, identify potential issues, and optimize the query based on the estimated costs and row counts.
EXPLAIN ANALYZE is valuable when you want to measure a query's actual performance and identify performance bottlenecks. It provides accurate execution statistics, which can help fine-tune the query, identify slow steps, and make informed decisions about indexing or other optimizations.
For more reading, here’s the Postgres and MySQL documentation on EXPLAIN.
The EXPLAIN and EXPLAIN ANALYZE output
Let’s look at what you get when you run EXPLAIN [query] or EXPLAIN ANALYZE [query]. Here, we’re using the IMDB dataset, which you can get by following the instructions in our caching slow queries guide. We’ll EXPLAIN the first query from that guide:
EXPLAIN SELECT count(*) FROM title_ratingsJOIN title_basics ON
title_ratings.tconst = title_basics.tconstWHERE title_basics.startyear =
2000 AND title_ratings.averagerating > 5;
Here’s the output:
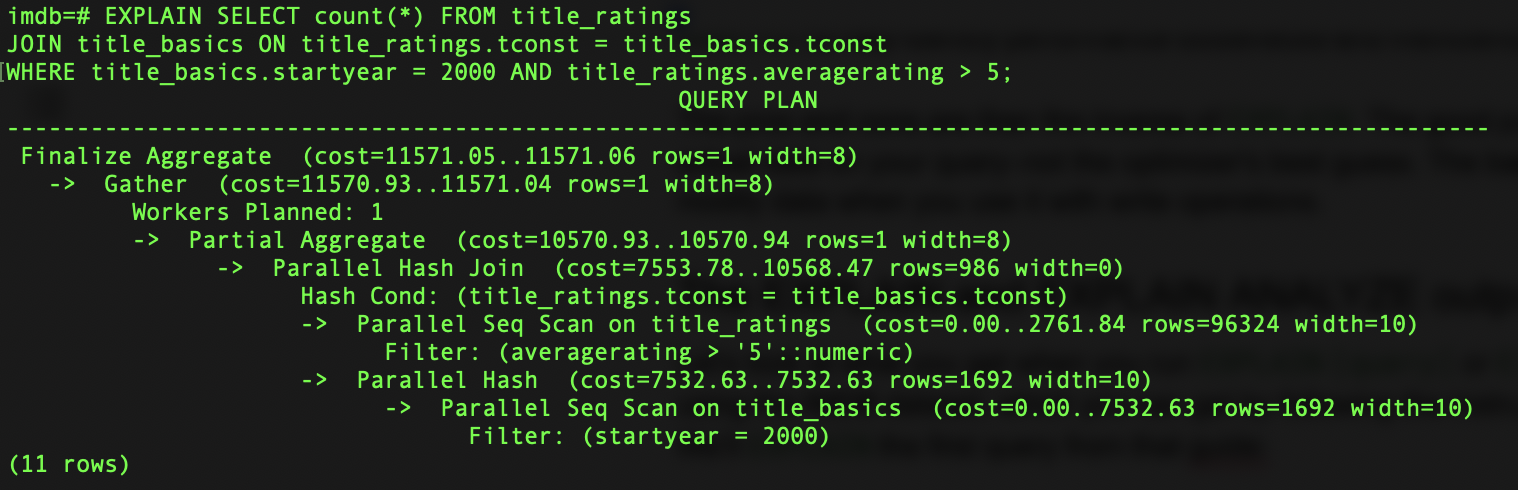
OK, so what does each row mean?
Finalize Aggregate (cost=11571.05..11571.06 rows=1 width=8): This is the final step of the query execution plan, which performs the final aggregation to count the number of rows. Here, the estimated cost range is from 11571.05 to 11571.06 units, and it is estimated that the result will be 1 row with a width of 8 bytes.Gather (cost=11570.93..11571.04 rows=1 width=8): This step gathers the results from parallel workers and indicates that the query uses parallel execution. The estimated cost range is from 11570.93 to 11571.04 units, and again, the optimizer estimates that 1 row will be gathered with a width of 8 bytes.- Workers Planned: 1: This line indicates that the query planner has used one parallel worker for the query execution.
Partial Aggregate (cost=10570.93..10570.94 rows=1 width=8): This step partially aggregates the results from the parallel workers, again with estimated costs and rows.**Parallel Hash Join (cost=7553.78..10568.47 rows=986 width=0)**: Here, we see how the query is actually being executed. This step performs a parallel hash join between thetitle_ratingsandtitle_basicstables. The join condition istitle_ratings.tconst = title_basics.tconstwith an estimated cost range from 7553.78 to 10568.47 units. It estimates that the join will produce 986 rows with a width of 0 bytes (no columns are selected from the join result).**Parallel Seq Scan on title_ratings (cost=0.00..2761.84 rows=96324 width=10)**: This step performs a parallel sequential scan on the title_ratings table. It applies the filter conditionaveragerating > '5'::numericand has an estimated cost range for the scan from 0.00 to 2761.84 units. It estimates that the scan will produce 96324 rows with a width of 10 bytes.**Parallel Hash (cost=7532.63..7532.63 rows=1692 width=10)**: This step builds a parallel hash table on the results of thetitle_basicstable scan. The estimated cost is 7532.63 units, and it estimates that the hash table will contain 1692 rows with a width of 10 bytes.**Parallel Seq Scan on title_basics (cost=0.00..7532.63 rows=1692 width=10)**: This step performs a parallel sequential scan on thetitle_basicstable and applies the filter conditionstartyear = 2000. The estimated cost range for the scan is from 0.00 to 7532.63 units. It estimates that the scan will produce 1692 rows with a width of 10 bytes.
So, what does this tell us about our query? This output tells us that our query will perform a parallel hash join between the title_ratings and title_basics tables after doing parallel sequential scans on each table individually. The scans filter the rows before the join. While the overall cost estimates are high, the key things to note are the hash join, which can be expensive, and the sequential scans, which indicate a lack of useful indexes that could speed up the filtering and joins.
Let’s now do the same thing with EXPLAIN ANALYZE:
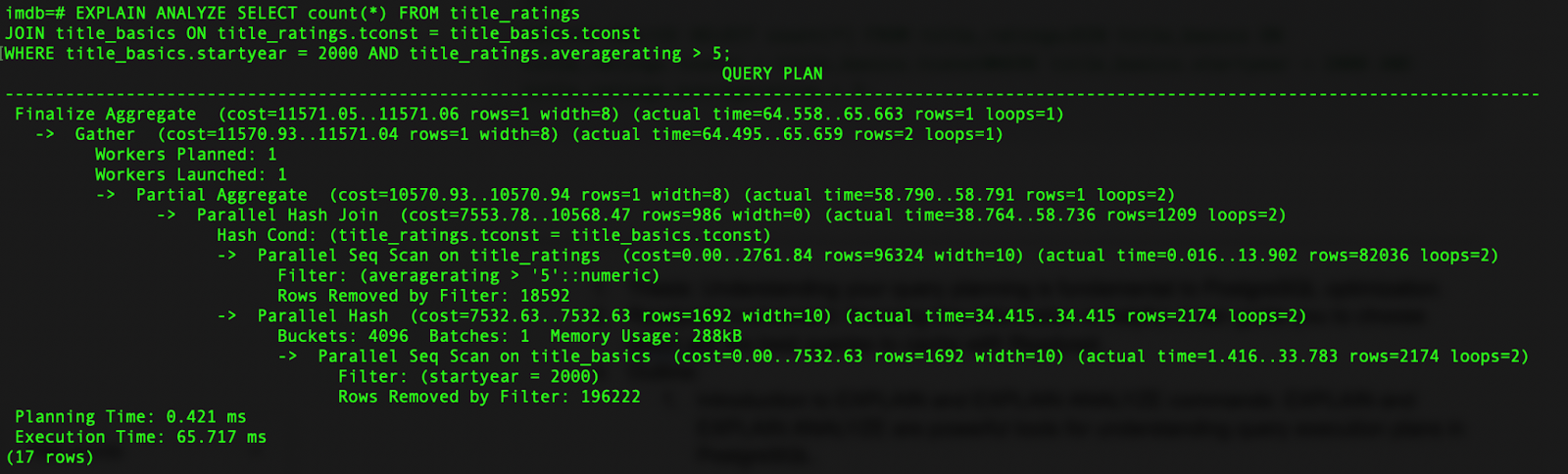
A lot of this information is the same as that in EXPLAIN. The optimizer did some good planning, though some row numbers were wrong.
But EXPLAIN ANALYZE adds the actual timings, which we can use to understand how our query was executed:
| Step | Actual Time |
|---|---|
| Finalize Aggregate | 64.558..65.663 |
| Gather | 64.495..65.659 |
| Partial Aggregate | 58.790..58.791 |
| Parallel Hash Join | 38.764..58.736 |
| Parallel Seq Scan on title_ratings | 0.016..13.902 |
| Parallel Hash | 34.415..34.415 |
| Parallel Seq Scan on title_basics | 1.416..33.783 |
The times here are "startup time".."total time" in milliseconds. A few key things stand out in this timing data:
- The
Parallel Hash Joinstep takes the most time (38ms to start up and 20ms to complete). This confirms that the hash join between the two tables is an expensive operation and a potential bottleneck. - The
Parallel Seq Scan on title_basicstakes significant time (1-33 ms). This suggests that filtering the title_basics table based on the startyear condition without an appropriate index is costly. - The
Parallel Hashstep also takes a notable time to start up (around 34 ms), indicating the overhead of building the hash table for the join. - In comparison, the
Parallel Seq Scan on title_ratingsis relatively faster (0-13 ms), likely because theaverageratingcondition is more selective and reduces the number of rows scanned.
These execution times provide valuable insights into the query's performance bottlenecks. They highlight that the hash join and the sequential scans, particularly on the title_basics table, are the main contributors to the query execution time.
To optimize this query, you could consider adding indexes on the frequently used columns (title_basics.startyear and title_ratings.averagerating) to speed up the filtering and join operations. Additionally, if the join between these tables is standard, denormalizing the tables or using a different join algorithm (e.g., merge join) could improve performance.
Improving Performance with Readyset
Understanding your query performance is an integral part of building with SQL. You want to know how your queries are executed, identify potential bottlenecks, and optimize them for better performance. EXPLAIN and EXPLAIN ANALYZE are powerful tools that provide valuable insights into the inner workings of your queries.
But there are problems with such optimizations:
- They only take you so far. For instance, adding the indexes to
title_basics.startyearandtitle_ratings.averageratingonly speeds up our performance from ~65 milliseconds to ~45 milliseconds. - There are diminishing returns. Adding those indexes takes less than a minute for a 20ms bump in performance. But to go further, you need to start drilling into how you can optimize your queries. This takes time away from other engineering needs and will only result in a few milliseconds gains.
Readyset allows you to improve performance drastically in about the time it takes to add those indexes. We have our IMDB database set up in a local Postgres instance. We can replicate that data within Readyset using:
docker run -d -p 5433:5433 -p 6034:6034 \
--name readyset \
-e UPSTREAM_DB_URL=<database connection string> \
-e LISTEN_ADDRESS=0.0.0.0:5433 \
readysettech/readyset:latest
This will connect to our database and replicate the tables. We can then log into Readyset in the same way we would our primary database, as Readyset is wire-compatible with Postgres:
psql 'postgresql://<username>:<password>@<readyset_host>:5433/<database>
We can then use CREATE CACHE FROM and our query above to create our cached query:
CREATE CACHE FROM SELECT count(*) FROM title_ratings JOIN title_basics ON
title_ratings.tconst = title_basics.tconst WHERE title_basics.startyear =
2000 AND title_ratings.averagerating > 5;
Now, if we run that query again, we can see that it is significantly faster through Readyset:
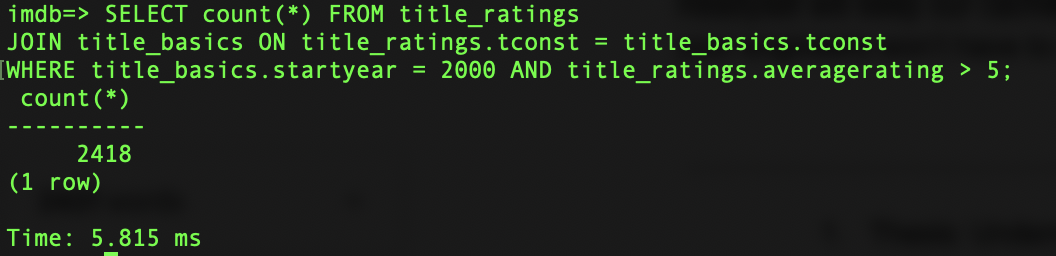
If we update the tables, Readyset will keep our cache up to date with no extra work on our side–the data will always be fresh, and the query will always be performant.
EXPLAIN and EXPLAIN ANALYZE are great tools–they are mainstays of any SQL usage. The problem is usually what follows. Engineers use the output to look for any marginal gain, trying to eke out a few extra milliseconds of performance from each line of the EXPLAIN ANALYZE output.
You should look for obvious optimizations, but you should also consider where time is better spent. Here, we’ve 10 X’ed our query performance without using any of the optimizations suggested by EXPLAIN ANALYZE, purely by caching our query with Readyset. Readyset gives you the performance increase but without the maintenance overhead that usually comes with caching.
If you need this for your application, you can start using Readyset today with our trial of Readyset Cloud. If you want to learn more, then reach out to us in Slack or book a demo to speak to us.
Related articles
Continue reading more about query optimization.

Query Optimization Readyset
Readyset
Readyset Now Supports SQL Window Functions.
We're excited to announce that Readyset now supports SQL Window Functions. This powerful addition means you can now cache more of your complex queries without modifying a single line of application code, bringing the performance benefits of Readyset to an even broader range of use cases. What Are Window Functions? Window Functions are one of SQL's most powerful features for analytical queries. They let you perform calculations across rows that are related to the current row, without needing c
2025-08-26·2 min read

Query Optimization Vinicius Grippa
Vinicius Grippa
Identifying Cacheable Queries: Using tools like pt-query-digest or the MySQL sys schema to pinpoint queries that would benefit from caching
Introduction It’s common for DBAs to optimize queries to address bottlenecks and reduce resource contention. However, in production workloads, the most resource-intensive queries aren’t always the longest-running ones. High-frequency queries that execute quickly but are called repeatedly can collectively consume significant resources, increasing overall latency and system load. Identifying these queries requires a more comprehensive analysis than simply inspecting the slow query log or process
2025-05-29·10 min read

Query OptimizationVinicius Grippa
Optimizing SQL Pagination in MySQL
In our blog post on Optimizing SQL Pagination in Postgres, we explained how to optimize SQL pagination for Postgres. As a counterpart, we’ve decided to write one for MySQL pagination. Like PostgreSQL, MySQL offers several ways to handle pagination, but some are far more efficient than others. Let's break down the SQL Pagination options, talk about why LIMIT and OFFSET can be a problem, and look at smarter ways to paginate large datasets efficiently. The Classic SQL Pagination Approach: LIMIT
2025-03-17·6 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.