← Back to blogAI & Databases
The Database Is About to Lose Its Last Line of Defense
For a long time, most serious database incidents shared a common root cause: a human made a mistake. It could be a poorly written query that caused a spike or a permission was too broad or maybe a review didn’t happen. Database security models, operational processes, and tooling were all built around that assumption. Humans were the risk, and humans were also the control. That assumption is starting to break down. Today, more and more SQL is generated without a human author. What used to be 1
Tanmay Sinha
2026-01-27 · 4 min read
For a long time, most serious database incidents shared a common root cause: a human made a mistake. It could be a poorly written query that caused a spike or a permission was too broad or maybe a review didn’t happen. Database security models, operational processes, and tooling were all built around that assumption. Humans were the risk, and humans were also the control.
That assumption is starting to break down.
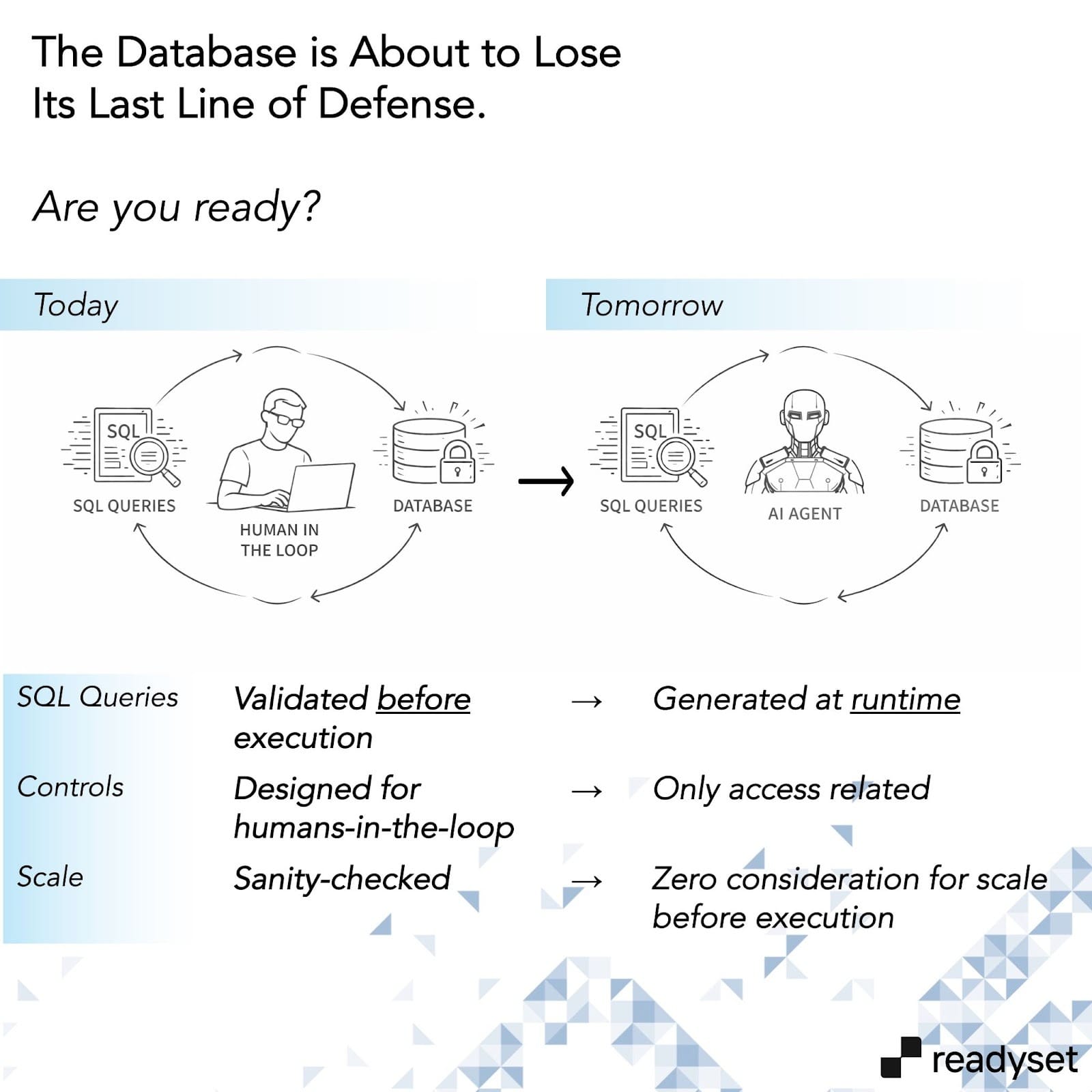
Today, more and more SQL is generated without a human author. What used to be 1) written during development, 2) reviewed before deployment, and 3) monitored during execution is now synthesized on demand by systems that may understand basic principles of database safety, compliance boundaries, or operational risk but lack contextual information needed to create the right query for the database.
The human checkpoint that databases control quietly depended on is going away.
This creates a new failure mode that most organizations are not prepared for: there is no longer meaningful control before a query executes. Queries are evaluated only after they run, based on their impact.
By that point, the arrow has already left the bow: the damage is already done.
The Query Lifecycle Is Breaking
Outside of database internals, SQL queries have always followed a fairly predictable lifecycle:
- Creation – at development time, where queries are written and refined
- Execution – at runtime, where applications are deployed and queries run in production
Both phases historically had clear human ownership.
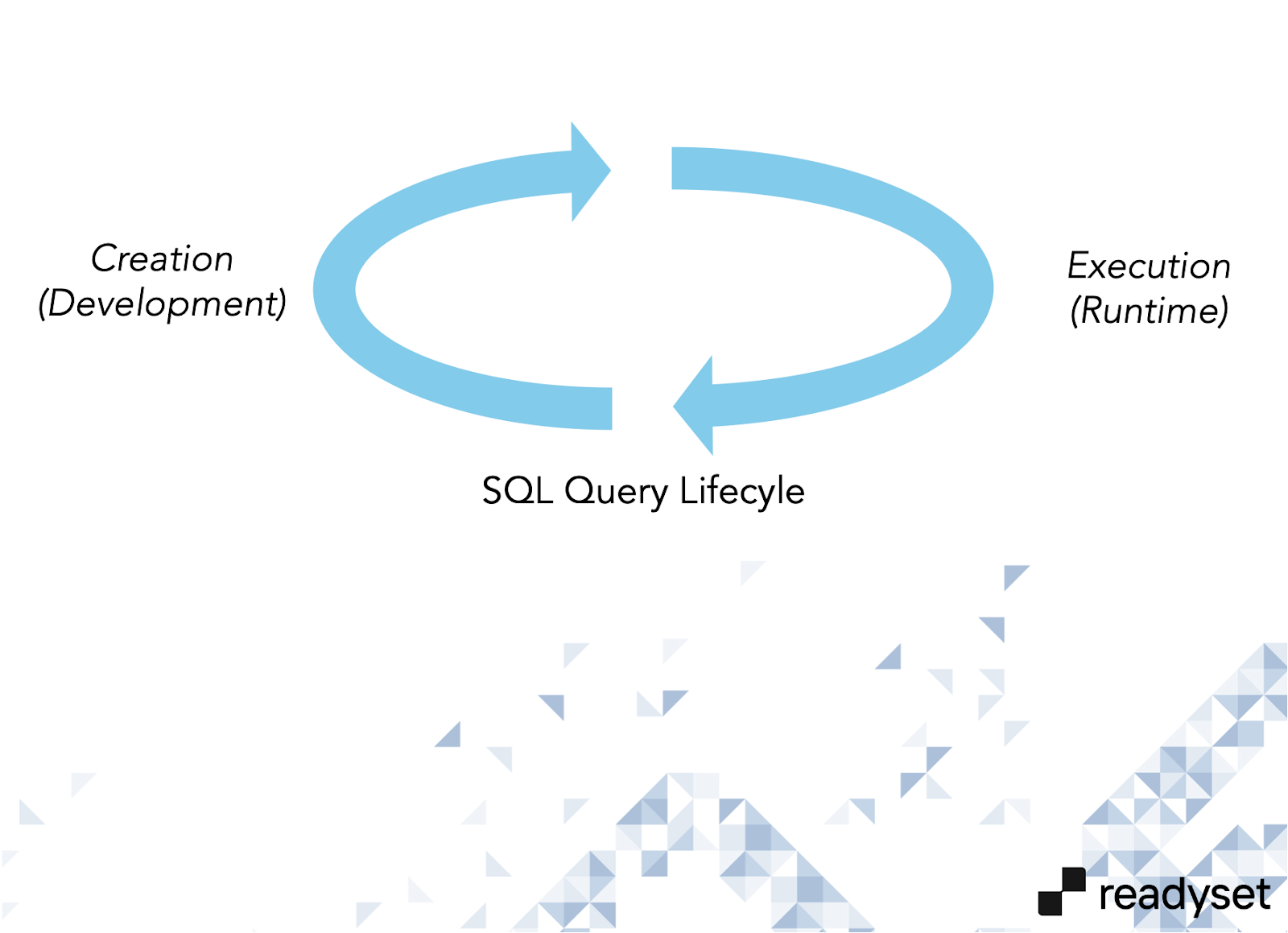
Early on, developers wrote SQL by hand. As applications grew, ORMs became the abstraction layer. The early days of ORMs were, frankly, the Wild West. Many applications built in the early 2010s are still weighed down by inefficient or opaque SQL generated by frameworks that prioritized developer velocity over database behavior. Over time, this improved as database experts got involved and teams learned where guardrails were needed.
LLMs brought another major shift.
Instead of abstracting SQL behind relatively static frameworks, we started generating SQL queries, on the fly, using AI. The abstraction still exists, but the author is no longer predictable or accountable. Even with vibe coding, however, there was always a human responsible for basic query sanity.
That is no longer true.
With agentic systems, the human-in-the-loop disappears entirely. Ephemeral SQL is generated at runtime by systems operating against databases they have never seen before. There is no built-in understanding of what is safe, compliant, or operationally reasonable for the underlying database.
The only feedback loop is execution.
Creation and execution effectively collapse into one step. Governance before execution is now dealing with consequences after something breaks.
Agentic Workloads Break Database Assumptions
AI-generated workloads behave fundamentally differently from traditional applications. They do not follow fixed execution paths or predictable access patterns. They iterate, retry, broaden scope, and optimize for completeness rather than restraint.
A request that looks harmless - analyze trends, find anomalies, summarize behavior - can easily translate into SQL that scans years of data, touches regulated fields, joins tables in unexpected ways, and runs repeatedly until the agent converges on an answer.
From the database’s point of view, these queries are valid. They use legitimate credentials, respect schema permissions, and are syntactically correct.
From the organization’s point of view, they expose a new uncontrolled risk surface.
This is not hypothetical. In 2025, several organizations reported incidents where AI coding assistants, operating with legitimate access and no malicious intent, deleted real production data while trying to fix problems that didn’t exist. There was no exploit, no breach, and no obvious policy violation. Just automated systems acting faster than humans could intervene.
This Is Not a Performance Problem
Performance is usually the first thing people notice, but it’s not the core issue.
When machine-generated queries overload a system, that’s an outage. When they surface sensitive or regulated data, that’s a breach. When they run continuously, legitimately, and without oversight, that’s a governance failure.
Existing controls weren’t designed for this. Permissions answer who can connect, not whether a specific query should run. Caching reduces load but doesn’t prevent unsafe access. Rate limits slow things down but can’t tell the difference between useful exploration and dangerous behavior.
None of these mechanisms answer the question that now sits squarely with platform, data, and security teams:
Who is responsible for ensuring that machine-generated queries are safe, compliant, and appropriate before they execute?
In most organizations today, the honest (and dangerous) answer is: no one.
It is Already in Production
This doesn’t require fully autonomous systems or some future architecture. Any organization deploying LLM-powered internal tools, AI copilots connected to live data, automated analytics, or customer-facing AI features backed by production databases has already crossed this line.
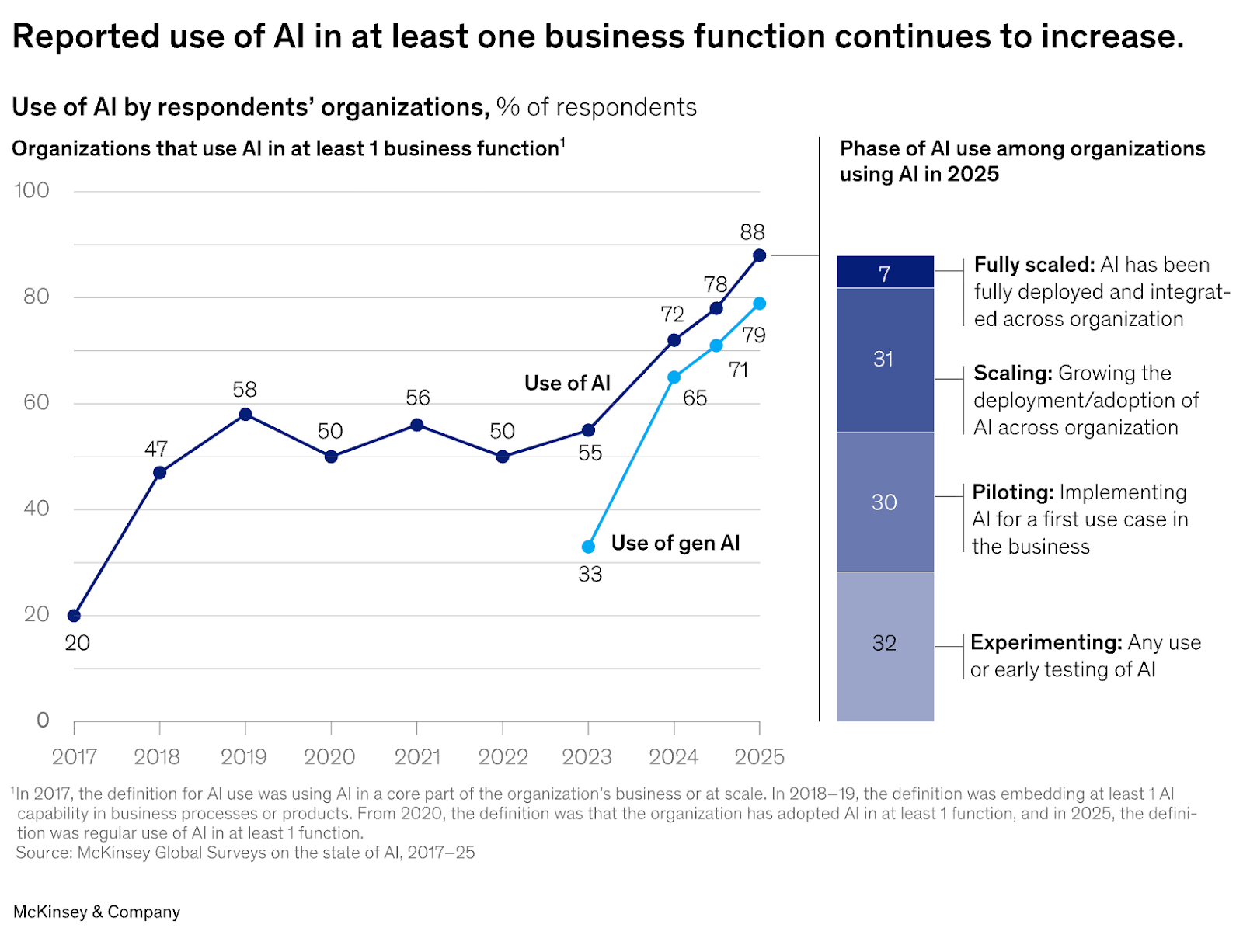
Source: The state of AI in 2025: Agents, innovation, and transformation, McKinsey Survey 2025
The exposure exists today. The only thing missing is visibility - and by the time you have visibility, the query has already run.
Databases were never designed to defend themselves against intelligent, autonomous query generators. They enforce permissions and constraints, but they don’t understand intent. As AI systems become first-class actors in data access, that gap becomes one of the most consequential and least discussed risks in the modern data stack.
The question is no longer whether databases will be stressed or misused by AI-generated workloads. That is already happening. The real question is whether organizations will reassert control - restoring governance before execution - before this becomes the new normal.
All is not lost. This is a solvable problem. The industry is just starting to recognize it, and the next layer of data infrastructure will be built to close this gap.
Note: AI was used to proofread this post.
Related articles
Continue reading more about ai & databases.

AI & Databases Readyset
Readyset
Why LLMs Write Incorrect SQL (and What That Means for Your Database)
Most LLM-generated SQL doesn't fail. It runs and returns results, and that's exactly what makes it dangerous. The errors don't surface until they're already in your data. AI-assisted development has made it easier than ever to generate SQL quickly. The problem is that quick and correct are not the same thing, and with databases, the gap between the two has consequences that compound quietly over time. SQL that runs is not the same as SQL that works. LLMs are good at producing SQL that looks ri
2026-04-23·5 min read

AI & Databases Vinicius Grippa
Vinicius Grippa
Vibe Coding a High-Performance App with Readyset QueryPilot
In this blog post, we are going to use "Vibe Coding" to build an application and explore Readyset QueryPilot, a tool designed to automatically analyze and cache queries in a MySQL workload. The goal is to prove that even for automated queries with no human interaction, QueryPilot can automate query caching and improve performance. QueryPilot automatically identifies which queries should be cached and recommends the appropriate strategy, either deep caching or shallow caching. This automation de
2026-02-24·6 min read

AI & Databases Gautam Gopinadhan
Gautam Gopinadhan
Predictions About the Effect of AI on Enterprise Software and Infrastructure
We embarked on an exercise to predict how Enterprise infrastructure (including data infrastructure), will change with AI. Along the way, we made several observations about software and processes in general. I'm noting some of these below. Some of these are fresh takes, and we haven't seen them discussed elsewhere, so we would love to hear different perspectives on them. In this article, we refer to both the use of AI to write software, as well as to execute processes and workflows, i.e. Agents.
Gautam Gopinadhan2026-01-07·5 min read
Still scaling the hard way?
Modern applications demand instant performance, even under unpredictable load. Readyset helps you eliminate slow queries, stabilize latency, and scale confidently.
Revolutionize your database performance with Readyset
Serve requests at sub-millisecond latencies with the modern database scaling and query caching system for MySQL and PostgreSQL.
Join our newsletter
Stay updated with the latest news, insights, and developments from Readyset — straight to your inbox.